Fuzzer
这是在GitHub上,找到的一个在线的书籍,讲解Fuzz的
https://hub.gke2.mybinder.org/user/uds-se-fuzzingbook-ktofhf06/notebooks/docs/notebooks/Fuzzer.ipynb
简单来说, 就是随机生成字符串, 在接受输入的地方及进行测试. 并且对程序崩溃的原因进行整理.
发现的问题就包括了缓冲区溢出/缺少错误输入的检查/极端值的验证等常见的错误
Generic Checker(泛型检测器)
Memory Accesses
LLVM Address Sanitizer which detects a whole set of potentially dangerous memory safety violations. 将这个嵌入到c程序中,并进行编译, 当访问越界的地址时, 会提示报错, 被给出一个详细的说明.
![报错示意图]](https://laoba-1304292449.cos.ap-chengdu.myqcloud.com/img/20211119145215.png)
HeartBleed bug 就是这么被测试出来的. OpenSSl库里面的漏洞
Information Leak
信息泄露可能不仅仅出现访问非法的地址, 同样有可能出现在合法地址中. 如果合法地址中包含了不应该泄露的敏感信息. 这种情况下, Address Sanitizer不会报错, 因为访问的是”合法”地址.
要应对这样的问题, 需要检查返回的字符串中, 是否包含了不应该出现的信息

定制检查
充分地利用assertion, 检查重要函数的input和result. 充分使用assertion可以提高检测到泛型检查器无法检查到的错误.
Check the integrity of complex data structures
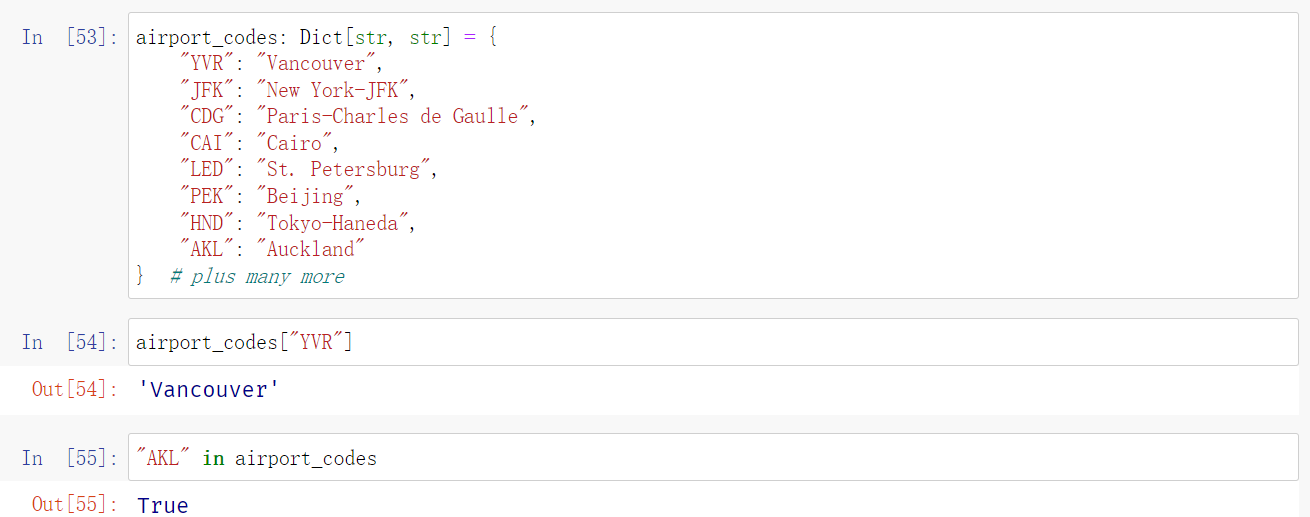
这个具体的检查,感觉就好像是编程中的问题, 要在改变重要数据结构前后, 都要验证数据结构的合法性. . Whenever an element is added or deleted, all these consistency checks are run automatically.
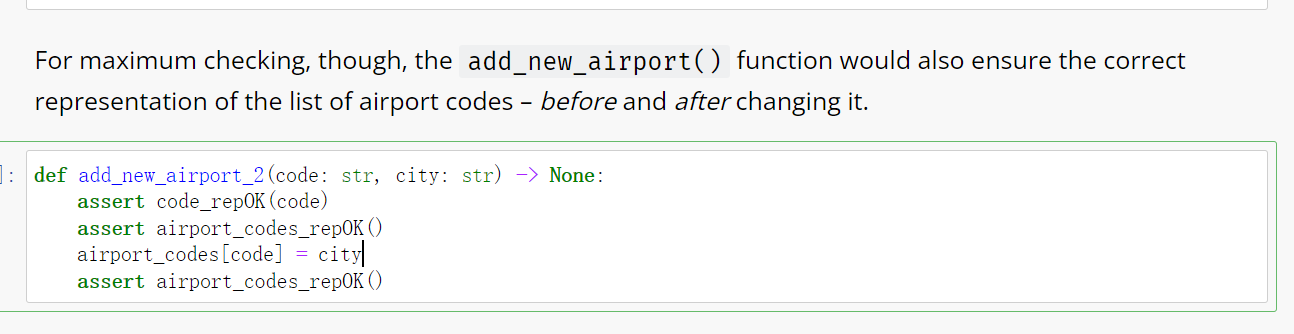
虽然这些检测 documents all the assumptions and checks them as well 仅仅针对于我们个人写的程序和问题, 但是可以帮助我们找到问题, 同时也能帮助其他程序员理解我们的代码并避免错误.
Fuzzing 结构
Fuzzer作为fuzzers的一个基类Runner作为运行程序和检测的一个基类
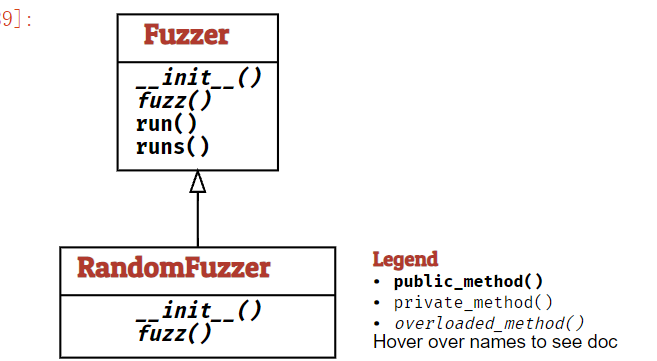
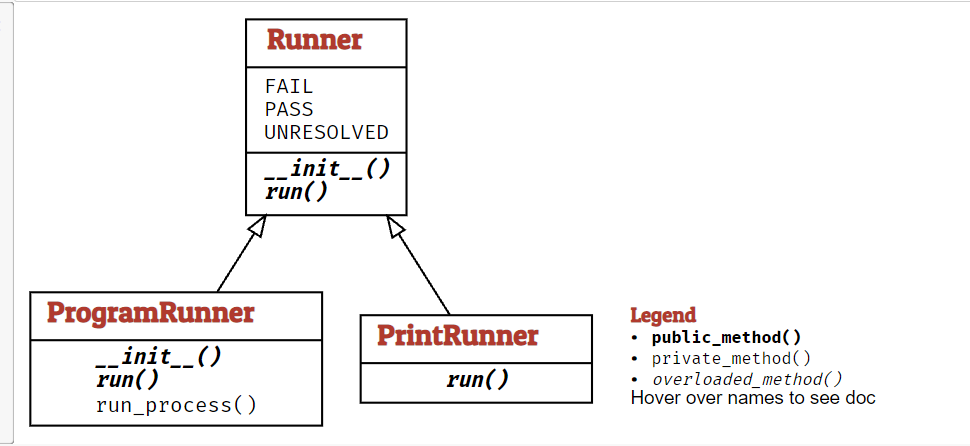
Lesson Learned
- Randomly generating inputs (“fuzzing”) is a simple, cost-effective way to quickly test arbitrary programs for their robustness.
- Bugs fuzzers find are mainly due to errors and deficiencies in input processing.
- To catch errors, have as many consistency checkers as possible.
Mutation-Based Fuzzing
这是上一本在结尾时推荐出来的
https://hub.gke2.mybinder.org/user/uds-se-fuzzingbook-whv6pm2k/notebooks/docs/notebooks/MutationFuzzer.ipynb
最初所生产出来的模糊字符串, 很多都是无效的. 在测验的过程中, 很快就被程序拒绝了. 现在提出的方法叫 基于突变的Fuzz, 要在现有输入上做微小的改动, 使其仍然保持有效性.
看到后面还得需要去在补前面的Code Coverage的定义😱😱😱😱
已补完😀😀
在知道这个Code Coverage之后呢, 我们就可以把通过检测以及Code Coverage有上升/或者从未出现过的fuzz字符串保存下来.
class MutationCoverageFuzzer(MutationFuzzer):
def reset(self):
super().reset()
self.coverages_seen = set()
# Now empty; we fill this with seed in the first fuzz runs
self.population = []
def run(self, runner):
"""Run function(inp) while tracking coverage.
If we reach new coverage,
add inp to population and its coverage to population_coverage
"""
result, outcome = super().run(runner)
new_coverage = frozenset(runner.coverage())
if outcome == Runner.PASS and new_coverage not in self.coverages_seen:
# We have new coverage
self.population.append(self.inp)
self.coverages_seen.add(new_coverage)
return resultThe nice thing about this strategy is that, applied to larger programs, it will happily explore one path after the other – covering functionality after functionality. All that is needed is a means to capture the coverage.
Lessons Learned
- Randomly generated inputs are frequently invalid – and thus exercise mostly input processing functionality.
- Mutations from existing valid inputs have much higher chances to be valid, and thus to exercise functionality beyond input processing.
Code Coverage
如何衡量这些测试的有效性?一种方法是检查发现的漏洞的数量(和严重性);但是如果bug非常少,我们就需要一个代理来确定通过测试发现bug的可能性。在这一章中,我们介绍了代码覆盖率的概念,衡量在测试运行期间程序的哪些部分实际上被执行了。对于试图覆盖尽可能多的代码的测试生成器来说,度量这样的覆盖率也是至关重要的。
黑盒测试
黑盒测试的优点是可以在指定的行为中发现出错误. 缺点是 以实现的行为通常比指定的行为覆盖更多的领域, 因此仅基于规范的测试通常不能覆盖所有的实现细节.
这话没毛病,毕竟是黑盒测试, 也仅仅只能通过函数的行为来进行测试. 并不能窥探到所有的实现细节.
白盒测试
白盒测试的优点是它可以找到以实现的功能里面的错误. 即使规范中没有提供详细的细节. 但是它可能会漏掉没有实现的行为.如果有些特定的功能没有实现, 白盒测试就不能找到它.
这最后一句话确定不是废话吗? 没实现就没有代码, 没有代码 那白盒测试肯定是测试不到的啊! 是我理解有问题吗?
运行时跟踪
这里介绍了py中的一个函数sys.settrace(f), 这个函数在程序运行的每一行都会调用.可以用它来获取执行程序的行数\当前属于哪个函数体\当前的局部变量和参数
当然C语言里面也有, 只不过要在编译的时候加一些参数, 然后运行之后,会产生
.gcov的文件,里面包含了类似py中sys.settrace()函数捕捉到的信息
![sys.settrace()的运行效果]](https://laoba-1304292449.cos.ap-chengdu.myqcloud.com/img/20211120205202.png)
Lessons Learned
- Coverage metrics are a simple and fully automated means to approximate how much functionality of a program is actually executed during a test run.
- A number of coverage metrics exist, the most important ones being statement coverage and branch coverage.
- In Python, it is very easy to access the program state during execution, including the currently executed code.

