NoteBook阅读
- 这一部分还是要再看看代码才行
Greybox Fuzzing
Blackbox Mutation-base Fuzzer
在这个测试里面,似乎只要是在population里面的seed,在权重上是一样的,换句话说就是被挑选的概率是一样的.
不过,按照我的理解, 按说这个权重应该是要变化的,可能在后面的讲解中会讲到吧
Greybox Mutation-base Fuzzer
我丢,从代码的角度上来看的话,灰盒测试无非是把代码覆盖率当成了加入population的一个准则
原话: If we reach new coverage,add inp to population and its coverage to population_coverage
Boosted Greybox Fuzzer
果不其然, 这个增强版的就用到了energy,也就是上面所讲的权重,它用了一个函数来计算.

这个指数后面文章所取的值是5
❓我不太清楚是, coverage只是一个数字, 如果只是数字的话, 那如何衡量路径呢? 因为即使是路径不同, coveraige也有可能是一样的.
emm,很明显,
coverage应该不仅仅是数字,他应该是(执行函数名,行数)这样的结构组成的😨
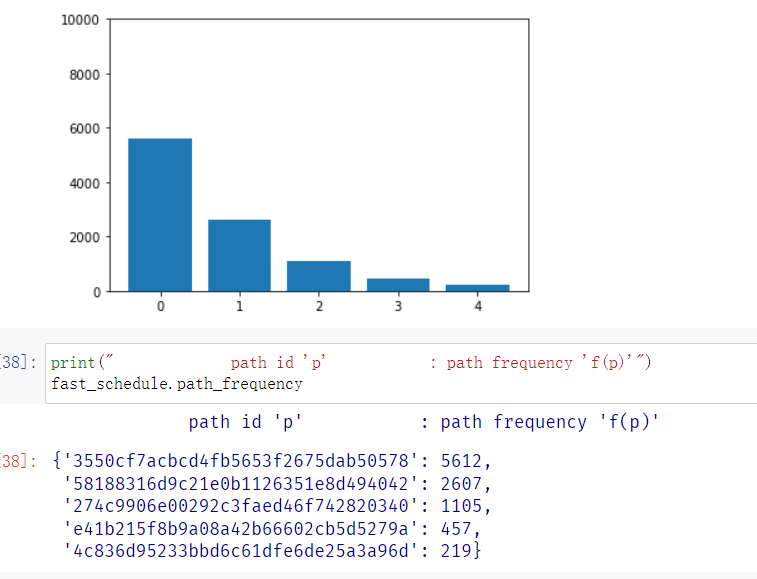
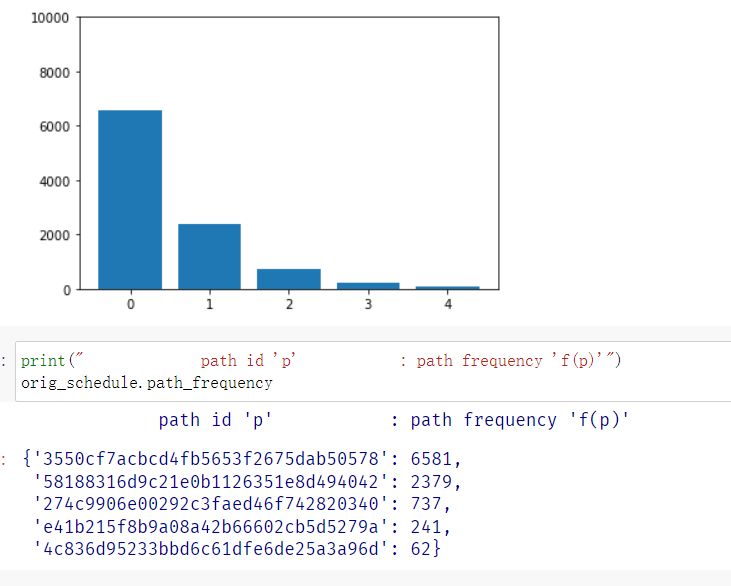
把energy分配给哪些执行次数相对较少的路径上, 以期再获得其他路径.
The exponential power schedule shaves some of the executions of the “high-frequency path” off and adds them to the lower-frequency paths. The path executed least often is either not at all exercised using the traditional power schedule or it is exercised much less often.
Summary. By fuzzing seeds more often that exercise low-frequency paths, we can explore program paths in a much more efficient manner.
Directed Greybox Fuzzing
本章用了一个迷宫来做案例, 迷宫的正确解恰恰对应于程序运行过程中运行次数最少的.
然后, 如何去评价一个路径的好坏, 本章节中采用了将程序调用图转换为有向图, 然后计算路径最终节点与目标节点-出口之间的距离.很显然这个距离越小, 说明距离目标节点-出口越近, 也就越接近出口.
Summary. After pre-computing the function-level distance to the target, we can develop a power schedule that assigns more energy to a seed with a smaller average function-level distance to the target. By normalizing seed distance values between the minimum and maximum seed distance, we can further boost the directed power schedule.
这部分说实话,真的没看懂..😥😥😥😥
Lessons Learned
- A greybox fuzzer generates thousands of inputs per second. Pre-processing and lightweight instrumentation
- allows to maintain the efficiency during the fuzzing campaign, and
- still provides enough information to control progress and slightly steer the fuzzer.
- The power schedule allows to steer/control the fuzzer. For instance,
- Our boosted greybox fuzzer spends more energy on seeds that exercise “unlikely” paths. The hope is that the generated inputs exercise even more unlikely paths. This in turn increases the number of paths explored per unit time.
- Our directed greybox fuzzer spends more energy on seeds that are “closer” to a target location. The hope is that the generated inputs get even closer to the target.
- The mutator defines the fuzzer’s search space. Customizing the mutator for the given program allows to reduce the search space to only relevant inputs. In a couple of chapters, we’ll learn about dictionary-based, and grammar-based mutators to increase the ratio of valid inputs generated.
从这也可以看出来,评价函数确实很重要. 虽然实现的目的都是一样的, 但是就实验的效果来看的话, 却是相差很远.
Next Steps
Our aim is still to sufficiently cover functionality, such that we can trigger as many bugs as possible. To this end, we focus on two classes of techniques:
Try to cover as much specified functionality as possible. Here, we would need a specification of the input format, distinguishing between individual input elements such as (in our case) numbers, operators, comments, and strings – and attempting to cover as many of these as possible. We will explore this as it comes to grammar-based testing, and especially in grammar-based mutations.
Try to cover as much implemented functionality as possible. The concept of a “population” that is systematically “evolved” through “mutations” will be explored in depth when discussing search-based testing. Furthermore, symbolic testing introduces how to systematically reach program locations by solving the conditions that lie on their paths.
These two techniques make up the gist of the book; and, of course, they can also be combined with each other. As usual, we provide runnable code for all. Enjoy!
从这里的描述来看,
specified functionality和implemented functionality是不同的两个概念
看到现在的话,其实作者的思路,我们大概也清楚的知道了一些
- 我们只是简单地随机产生字符串
- 紧接着, 我们不满足于仅仅产生随机的字符串, 进而使用了
coverage—measure the effectiveness of different test generation techniques, but also to guide test generation towards code coverage.
- 紧接着, 我们不满足于仅仅产生随机的字符串, 进而使用了
- 有了
coverage之后, 还不行, 因为总有一些路径几乎不被执行, 相反一些路径被执行的次数却很多. 倒也不是说这样不好, 只是By fuzzing seeds more often that exercise low-frequency paths, we can explore program paths in a much more efficient manner.所以又引入了Power SchedulesWe call the likelihood with which a seed is chosen from the population as the seed’s energy. Throughout a fuzzing campaign, we would like to prioritize seeds that are more promising. Simply said, we do not want to waste energy fuzzing non-progressive seeds. We call the procedure that decides a seed’s energy as the fuzzer’s power schedule. For instance, AFL’s schedule assigns more energy to seeds that are shorter, that execute faster, and yield coverage increases more often.
- 有了
- 但是有了这些还是不行, 因为虽然产生的随机字符串有了一定的质量, 但是在语法上, 还是比较欠缺.
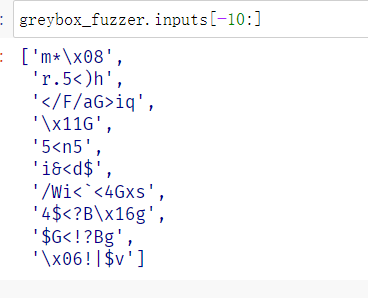
The greybox fuzzer executes much more complicated inputs, many of which include special characters such as opening and closing brackets and chevrons (i.e., <, >, [, ]). Yet, many important keywords, such as are still missing.
所以,下面一章就要将
grammars的部分了- 但是有了这些还是不行, 因为虽然产生的随机字符串有了一定的质量, 但是在语法上, 还是比较欠缺.
