毕设-Fuzz-AFLGo源码阅读-4
AFLGo在AFL的基础上的改进
添加了模拟退火算法, 根据种子距离目标节点的距离来
1. 具体的距离目标taget的距离是怎么计算的
2. 模拟退火算法, 是如何逐步退火?&& 是怎么挑选种子的?
AFL 的calculate_score函数是对 seed 进行打分,打分的分数决定对 seed fuzzing的时间长度,按照直觉来说,距离越近的 seed,有更大的概率能够到达目标点,则应该分配更多的时间给这些 seed。但是这样就会陷入上面所说的局部最优的困局里,于是 AFLGo 采用时间作为一个划分阶段的 metric,当 fuzzing 的时间在预定的时间内时,让时间较为公平的分配给每个 seed 上,当 fuzzing 时间超过了预定的时间后,时间就集中分配给哪些距离较近的 seed 上。这样可以在前期避免还未广泛探索就过度集中的局部最优的情况。
u64 cur_ms = get_cur_time();
u64 t = (cur_ms - start_time) / 1000;// 计算当前运行时间
double progress_to_tx = ((double) t) / ((double) t_x * 60.0);// 进度条,距离利用阶段的比例还有多少
double T;
//TODO Substitute functions of exp and log with faster bitwise operations on integers
// 这里根据fuzzing前的选项选择冷却时间的模型,是log函数,还是线性,还是指数等等
switch (cooling_schedule) {
case SAN_EXP:
T = 1.0 / pow(20.0, progress_to_tx);
break;
case SAN_LOG:
// alpha = 2 and exp(19/2) - 1 = 13358.7268297
T = 1.0 / (1.0 + 2.0 * log(1.0 + progress_to_tx * 13358.7268297));
break;
case SAN_LIN:
T = 1.0 / (1.0 + 19.0 * progress_to_tx);
break;
case SAN_QUAD:
T = 1.0 / (1.0 + 19.0 * pow(progress_to_tx, 2));
break;
default:
PFATAL ("Unkown Power Schedule for Directed Fuzzing");
}
double power_factor = 1.0;
if (q->distance > 0) {
// 首先归一化距离
double normalized_d = 0; // when "max_distance == min_distance", we set the normalized_d to 0 so that we can sufficiently explore those testcases whose distance >= 0.
if (max_distance != min_distance)
normalized_d = (q->distance - min_distance) / (max_distance - min_distance);
if (normalized_d >= 0) {
double p = (1.0 - normalized_d) * (1.0 - T) + 0.5 * T;// 计算p值,由距离和时间共同决定
power_factor = pow(2.0, 2.0 * (double) log2(MAX_FACTOR) * (p - 0.5));// 最后根据p值计算得到factor,
}// else WARNF ("Normalized distance negative: %f", normalized_d);
}
perf_score *= power_factor;// 乘上factor得到最后的score也就是说,得分score计算的公式是由距离和时间共同决定的,你要搞清楚,并不是每一次fuzz都会选择score分数最高的种子,而是分配更多的havoc时间给这样的seed。刚开始种子是比较公平的分配到每个seed,这类似–无差别探索阶段。后来,当预定的时间已过。距离较近的seed就会拥有更高的分数,从而在固定的时间段内占有更长时间的havoc,以增加到达taget的几率。
3. 一个是函数距离,一个是基本块之间的距离,这两个距离之间是如何作用的呢?
先看一下什么叫做控制流图
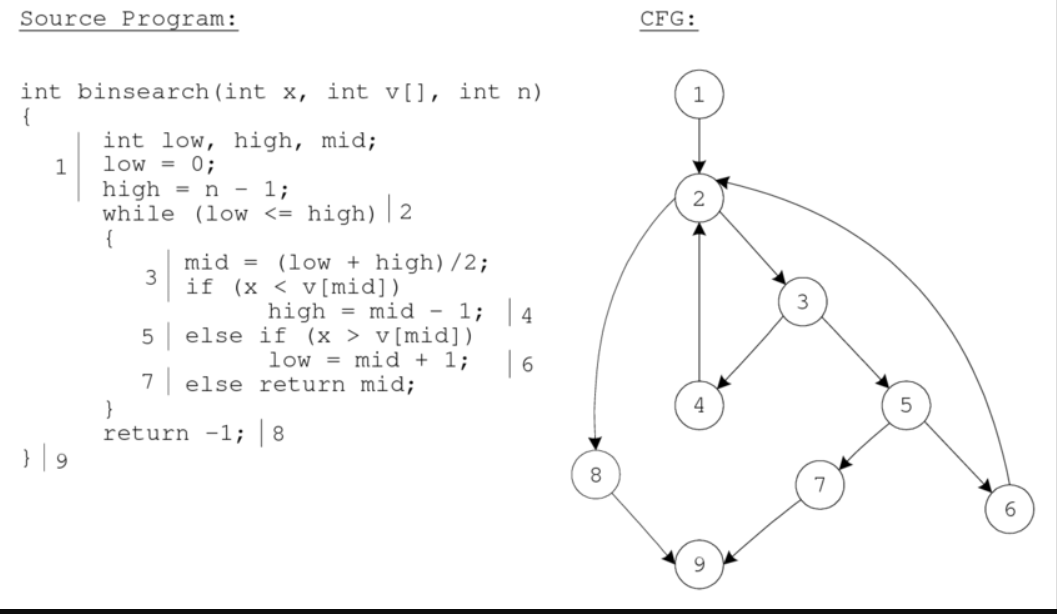
这两个是从源码角度分析的


结合的地方
Also, for each basic block in control flow graph of current function, we collect all functions it calls usingBBcalls.txt. Among these functions that havecg_distance, AFLGO get the minimum of these and setbb_distanceto it.
下面这两个估计是从论文角度分析的,那可能源码在实现上和论文有一定的区别。


4. 我应该怎么设计我的算法?
四个阶段
基于距离的模拟退火算法
- 无差别探索阶段 Undifferentiated Exploration
- 短路径优先阶段 Short Path Priority
基于基本块距离的模拟退火算法
- 长路径探索 Long Path Exploration
- 长路径优先 Long Path Priority
- 设置
bb_passed记录当前种子经过的基本块的数量 - 设置
is_longpathexploration当前这个种子是不是在长路径探索阶段被探索过
问题
calibrate_case 函数
里面 this calculates cur_distance这个看不懂啊,has_new_bits函数中包括了下面计算max_distance和min_distance的代码,为什么这里又再次包含了一遍。
程序中所谓的seed到底是什么?
是不同的测试文件,不是像你像的那样,从这个测试文件中读取内容然后再将一条条的内容进行测试
为什么按照步骤执行ReadMe中的测试步骤,却不能生成dot文件呢?
Linux
sudo
Sudo 的全称为:super user do。 顾名思义:干超级用户才能干的事!所以Sudo最常用的功能就是提升一个命名的执行权限。
C++
Vector
向量(Vector)是一个封装了动态大小数组的顺序容器(Sequence Container)。跟任意其它类型容器一样,它能够存放各种类型的对象。可以简单的认为,向量是一个能够存放任意类型的动态数组。

