效率提升
1
最初就是把算法跑通了,然后也没有什么bug了。
效果可以说是惨不忍睹, 跑三个半小时,还不如AFLGo跑十几分钟。
2
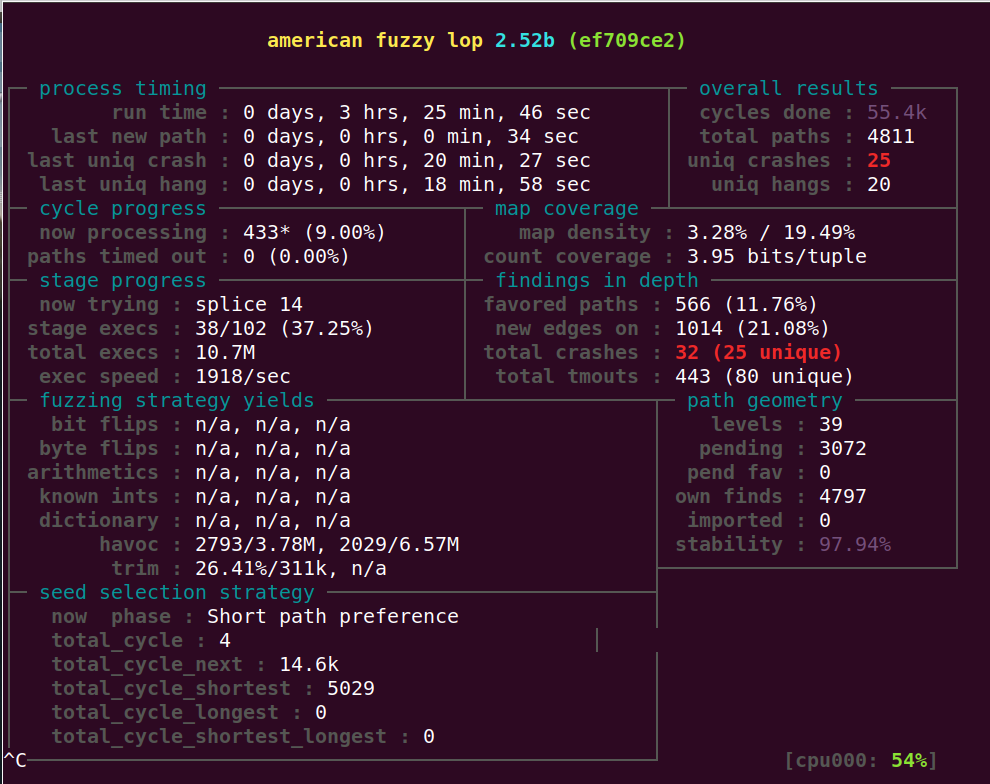
在fuzz_one中是有概率跳过代码的。我把这部分概率跳过的代码限制只在无差别探索阶段使用,效率提升了一些,但还远没有达到想要的效果。
既然这样的话,我又想着,应该是把概率跳过的代码限制在 无差别探索阶段 和 短路径优先阶段 都使用才对。
这样的效果也一般,跟上面的差不多。
3
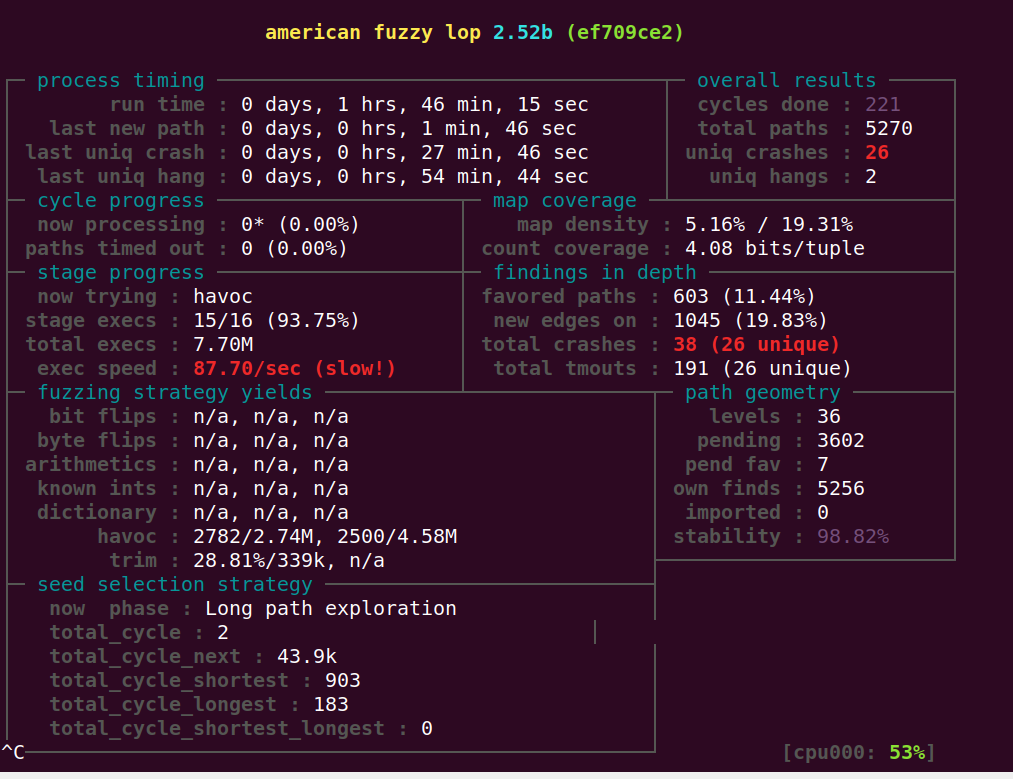
先从select_the_shortest开始优化,先优化寻找fuzz过的和没有fuzz过的。
用新的指针 temp_queue_fuzzed在第一遍循环的时候,就找到的已经被fuzzed过的种子。
直接把所有的handle函数都更换了,顺便修改if语句的条件控制,尽量让条件尽可能的为真。–但是真并不意味着一定是你想要的
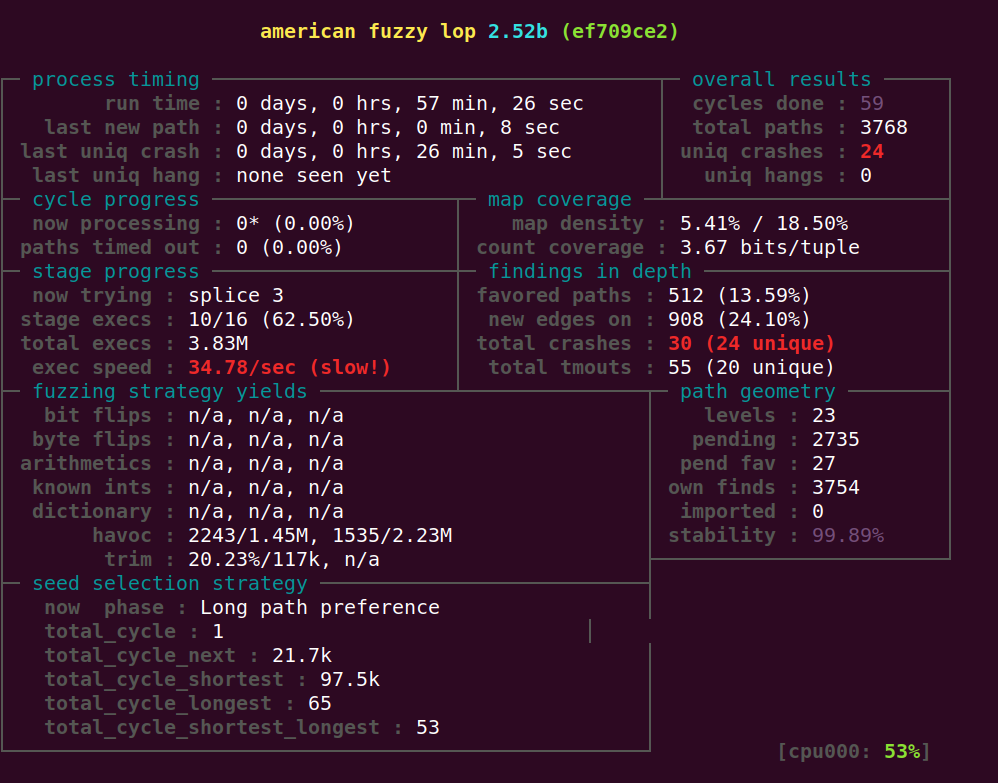
longest和shortest_longest两个阶段运行的次数太少,速度也很慢。 尤其是那个trim阶段,stage execs后面那个数很大。会有700多或者是800多。
4
鉴于,之前的算法非常慢。而且没有完全符合论文中的描述。所以我决定重新设计算法。
在算法的编写过程中,尤其是复用其他函数中的代码段时,总是会出现一些变量名忘记更改的问题。导致出现访问空指针的情况。(段错误)
还有,在加入队列(add_to_queue)的时候,对最大最小值进行判定没有问题。 可是我忽略了,在队列(calibrate_case)当中进行最大和最小值的更替。
我dnmd,速度上确实是快了一些,但是效率上咋变低了呢?
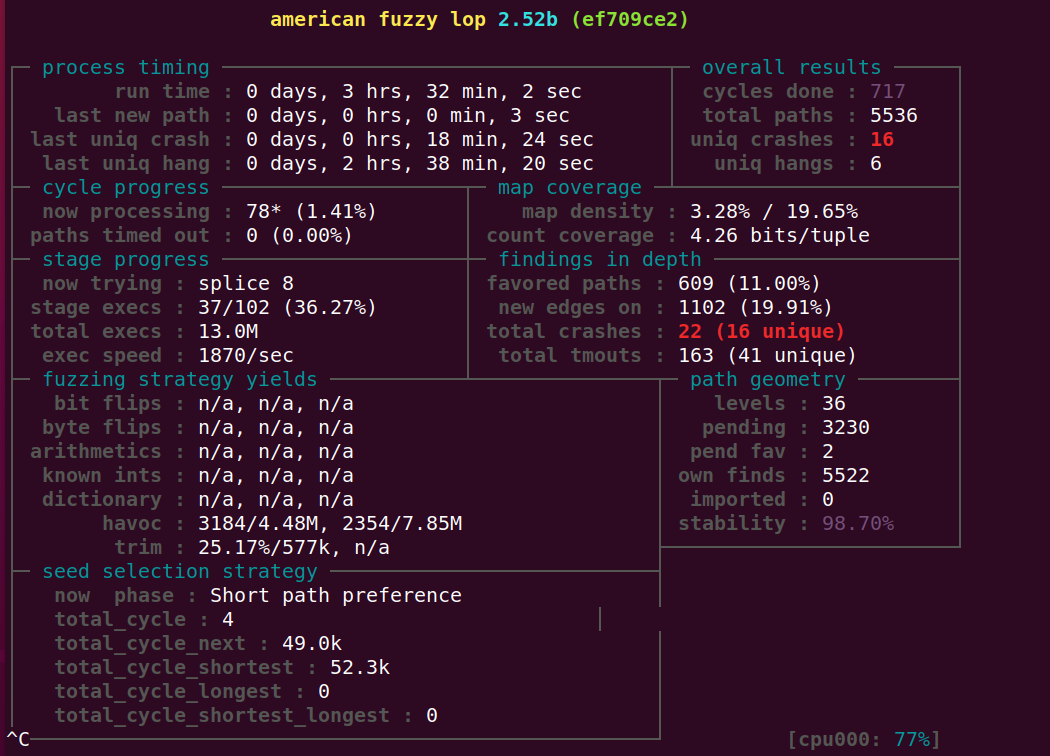
5
把论文中描述的在短路径优先阶段中,给予种子最大的能量给加进去了。效果依然不是很好。
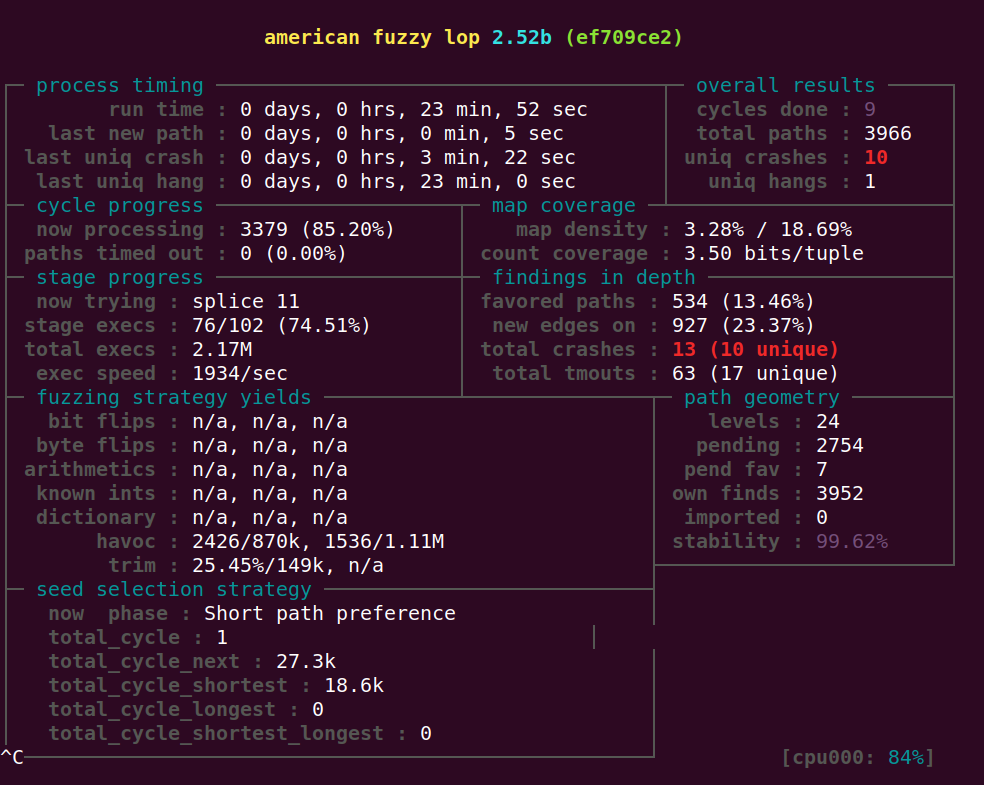
验证crash
pwndebug
即使是用正常的afl-fuzz跑出来的, 依然也只是有问题的输入样例。并不能产生像之前说的那种崩溃。 这种crash是如何计算的呢?
下一步思路
下一步:
继续优化短路径优先阶段。提高这个阶段的效率。
增加没有最短路径/最大基本块数的情况, 就是种子的值都还是-1的情况。
第二轮的效果,远远没有第一轮的效果好。
还有一个想法,我觉得我甚至可以把AFLGo的原理都写到毕业论文中。包括编译插桩是如何进行的,在运行的时候又是如何体现出来的。甚至包括forkserver与主进程之间的切换等等。
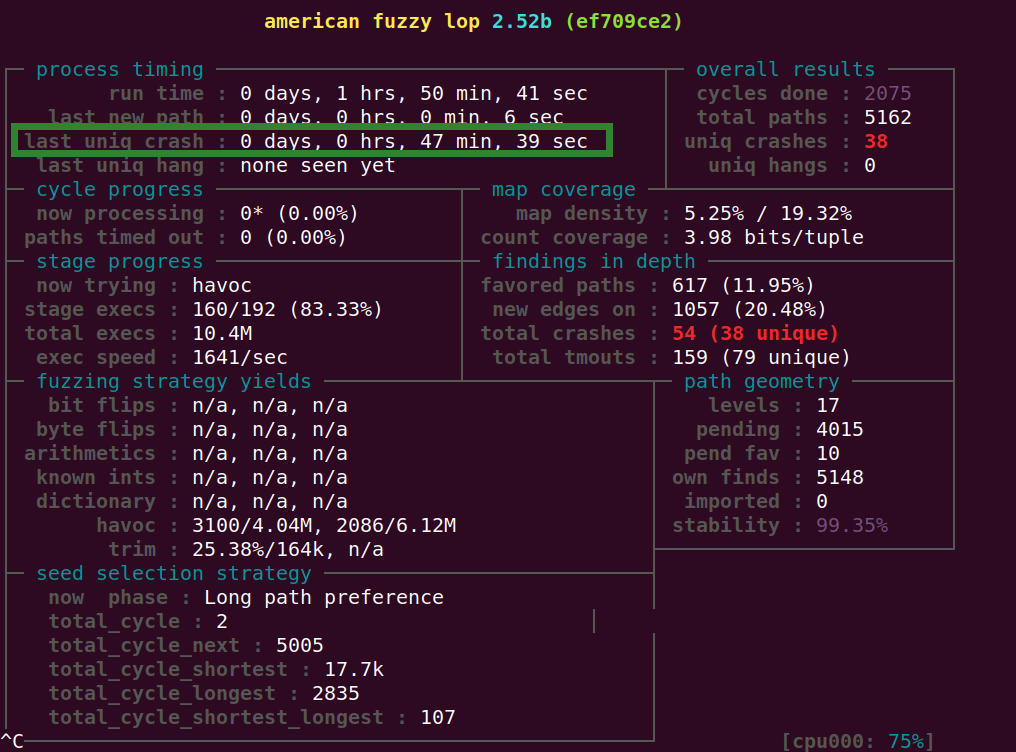
图片当中的54个crash甚至都是第一轮跑出来的。 想一想为什么第二轮的效果远远不如第一轮呢?
6
把短路径优先阶段的概率跳过给删去,再试一试。 —-但是这个好像不解决,第二轮的问题呀!
在最长的路径里面挑选最短的,又是段错误,我不知道为什么??
这样把,明天把时间管理的指针重新写一下。 尽量就是不要让他第一次就进入到第一个循环里面去。
为什么queue_max_bb 和queue_min_distance 有的时候为空指针?
因为下面这些代码—**has_new_bits()**函数里面的
if (*total_count > 0) {
cur_distance = (double)(*total_distance) / (double)(*total_count);
cur_bb = (double)(*total_count);
}
else{
cur_distance = -1.0;
cur_bb = -1.0;
}可以看到只有在 total_count > 0 的情况下,
cur_distance和cur_bb的值才会更新。否则他们就一直是-1。
而如果他们一直保持-1的值的话, 在calibrate_case()这个函数里面没有办法,更新 queue_max_bb 和 queue_min_distance 的指针 所以这两个指针就一直是空,就容易产生段错误。
if (q->distance <= 0) {
/* This calculates cur_distance */
has_new_bits(virgin_bits);
q->distance = cur_distance;
q->bb = cur_bb;
if (cur_distance > 0) {
if (max_distance <= 0) {
max_distance = cur_distance;
min_distance = cur_distance;
queue_min_distance = q;
}
if (cur_distance > max_distance) max_distance = cur_distance;
if (cur_distance < min_distance) { queue_min_distance = q; min_distance = cur_distance; }
}
if (cur_bb > 0) {
if (max_bb <= 0) {
max_bb = cur_bb;
min_bb = cur_bb;
queue_max_bb = q;
}
if (cur_bb > max_bb) { queue_max_bb = q; max_bb = cur_bb; }
if (cur_bb < min_bb) min_bb = cur_bb;
}
}那么问题就又来了,在什么情况下 total_count 的值会 >0 ? 这个问题恐怕要回到插桩代码中去了。
for (auto &F : M) {//文件中的所有函数
int distance = -1;
for (auto &BB : F) {//函数中的所有基本块
distance = -1;
if (is_aflgo) {
/*
这里获取每个基本块名字的方法和预处理阶段一样,取第一个有效指令的位置信息作为基本块名字
*/
std::string bb_name;
for (auto &I : BB) {
std::string filename;
unsigned line;
getDebugLoc(&I, filename, line);//获取指令所在的文件名和行数
if (filename.empty() || line == 0)
continue;
std::size_t found = filename.find_last_of("/\\");
if (found != std::string::npos)
filename = filename.substr(found + 1);
bb_name = filename + ":" + std::to_string(line);
break;
}
if (!bb_name.empty()) {
/*
比较名字是否相同判断是否是需要插桩的基本块
*/
if (find(basic_blocks.begin(), basic_blocks.end(), bb_name) == basic_blocks.end()) {
/* 如果开启AFLGO_SELECTIVE选项,则不进入后面插桩的逻辑部分,即AFL的逻辑也只对AFLGo选择的基本块插桩
*/
if (is_selective)
continue;
} else {
/* Find distance for BB */
/* 找到对应基本块的距离
*/
if (AFL_R(100) < dinst_ratio) {
std::map<std::string,int>::iterator it;
for (it = bb_to_dis.begin(); it != bb_to_dis.end(); ++it)
if (it->first.compare(bb_name) == 0)
distance = it->second;
}
}
}
}
/* 进入插桩的逻辑部分,前面的部分是AFL的basicblock edge插桩逻辑
*/
BasicBlock::iterator IP = BB.getFirstInsertionPt();
IRBuilder<> IRB(&(*IP));
if (AFL_R(100) >= inst_ratio) continue;
/* Make up cur_loc */
unsigned int cur_loc = AFL_R(MAP_SIZE);
ConstantInt *CurLoc = ConstantInt::get(Int32Ty, cur_loc);
/* Load prev_loc */
LoadInst *PrevLoc = IRB.CreateLoad(AFLPrevLoc);
PrevLoc->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
Value *PrevLocCasted = IRB.CreateZExt(PrevLoc, IRB.getInt32Ty());
/* Load SHM pointer */
LoadInst *MapPtr = IRB.CreateLoad(AFLMapPtr);
MapPtr->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
Value *MapPtrIdx =
IRB.CreateGEP(MapPtr, IRB.CreateXor(PrevLocCasted, CurLoc));
/* Update bitmap */
LoadInst *Counter = IRB.CreateLoad(MapPtrIdx);
Counter->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
Value *Incr = IRB.CreateAdd(Counter, ConstantInt::get(Int8Ty, 1));
IRB.CreateStore(Incr, MapPtrIdx)
->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
/* Set prev_loc to cur_loc >> 1 */
StoreInst *Store =
IRB.CreateStore(ConstantInt::get(Int32Ty, cur_loc >> 1), AFLPrevLoc);
Store->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
/*
下面是AFLGo的距离插桩部分,将该基本块的距离累加到MapDistLoc的位置上,再递增MapCntLoc位置的值,
即:MapDistLoc上的值表示seed经过所有的基本块的距离累加和,MapCntLoc上的值表示seed经过的基本块的数量。
*/
if (distance >= 0) {
ConstantInt *Distance =
ConstantInt::get(LargestType, (unsigned) distance);
/* Add distance to shm[MAPSIZE] */
Value *MapDistPtr = IRB.CreateBitCast(
IRB.CreateGEP(MapPtr, MapDistLoc), LargestType->getPointerTo());
LoadInst *MapDist = IRB.CreateLoad(MapDistPtr);
MapDist->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
Value *IncrDist = IRB.CreateAdd(MapDist, Distance);
IRB.CreateStore(IncrDist, MapDistPtr)
->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
/* Increase count at shm[MAPSIZE + (4 or 8)] */
Value *MapCntPtr = IRB.CreateBitCast(
IRB.CreateGEP(MapPtr, MapCntLoc), LargestType->getPointerTo());
LoadInst *MapCnt = IRB.CreateLoad(MapCntPtr);
MapCnt->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
Value *IncrCnt = IRB.CreateAdd(MapCnt, One);
IRB.CreateStore(IncrCnt, MapCntPtr)
->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
}
inst_blocks++;
}
}那如果total_count 的值为零的话,是不是说明这个种子压根就没有进入到程序中去?
我又尝试了一下对libxml2的调试, 因为对这个库进行fuzz的时候,种子是仓库中包含的。与预期的符合,可以看出distance和bb都是有值的
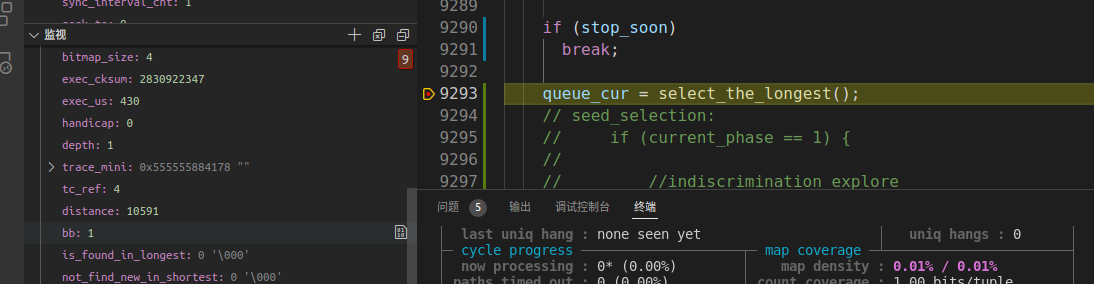
解决方案就是, 当你在使用这两个指针的时候,记得判断一下是否为空。
如果都为空的话,直接返回上一个被选中的种子。
7
现在有一个问题就是, queue_min_distance 和 queue_max_bb 经常是空指针, 这样就说明种子好像根本没有进到程序当中。
此外,cron的确是可以定时运行程序的,但是效果不是很好。一开始我是担心,cron启动的进程会不会在资源上有些受限,但是我再次在命令行运行之后,一个小时跑出来的结果居然才21. 也就是说目前AFLGo的运行效果并不稳定,时好时坏。
还是要当面监控运行效果,否则很难发现问题到底出在什么地方
短路径优先阶段中,没有发现更近的种子 和 没有发现新路径 这是两个不同的概念啊!
我觉得对这个概念理解的不同直接导致了编写的算法中 偏向了路径发现。 通过对比和师兄论文中描述的实验对比,可以发现,在
total_path这一指标上,很明显我的算法要比师兄的算法高。但这已经偏离了我们想要的效果。
calibrate_case和add_to_queue这两个函数发生的时机
我是这么理解的,
calibrate_case进行的时候,是针对所有已经添加到队列中的种子了。所以我觉得并不需要考虑calibrate_case阶段中min_distance是否改变了。save_if_interesting中调用add_to_queue的时候我们需要看一下min_distance是否发生改变。
select_shortest_from_longest函数中的min_distance_in_longest变量是否要更改成0xFFFFFFFF
把前面说的问题都改了,发现改了还不如不改。。。。 不过shortest阶段确实有一些进步。主要是以前无差别探索阶段总是可以探索出好多,但是现在无差别探索阶段探索不出来很多了。
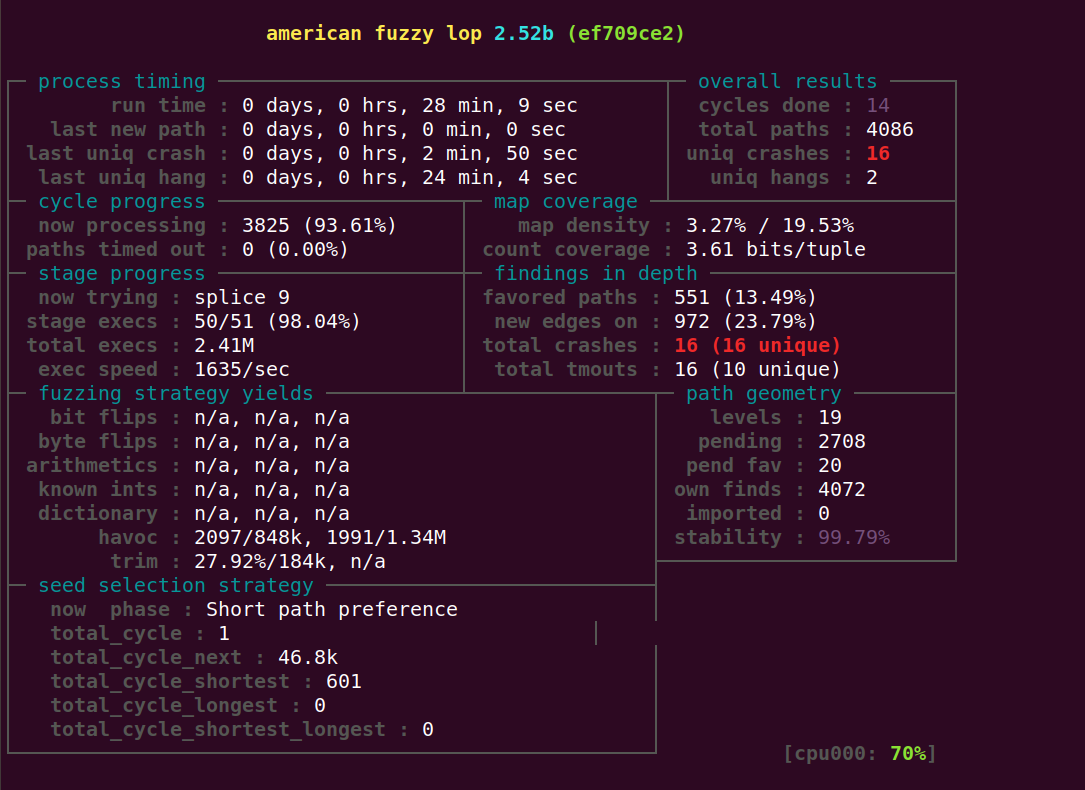
把短路径优先阶段直接改成–只接受更优解的情况之后,效果好了一些。
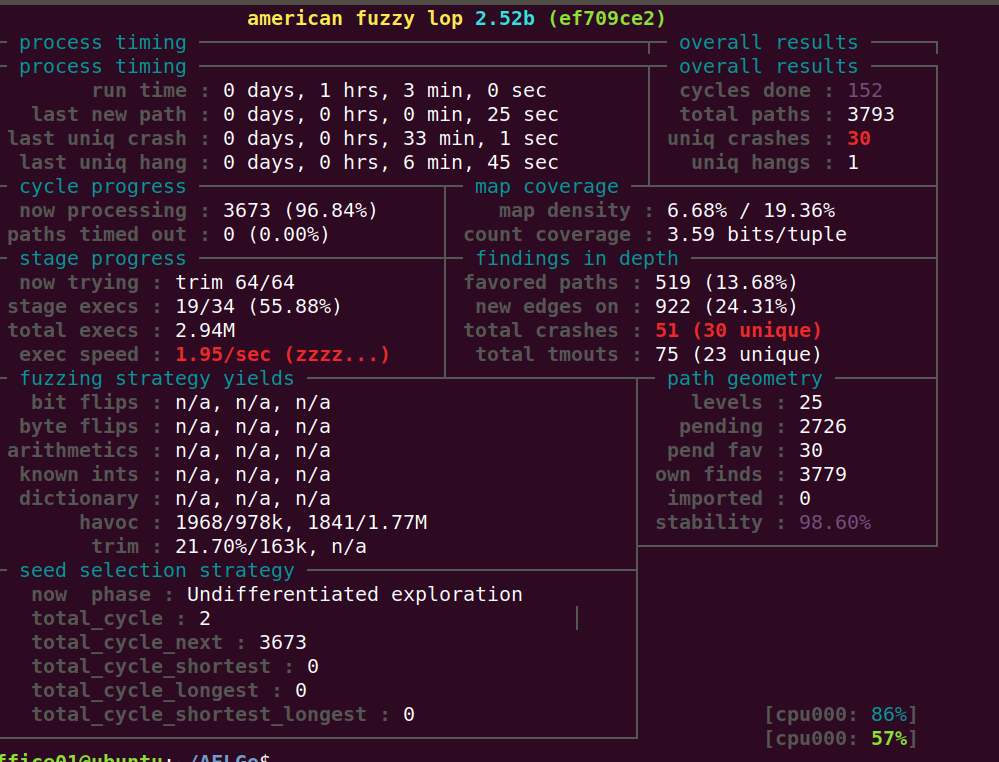
通过我的观察发现,短路径优阶段一直重复那两个种子。其他的种子得不到fuzz。——这个是因为current_entry除了第一阶段后面就没有再增加了
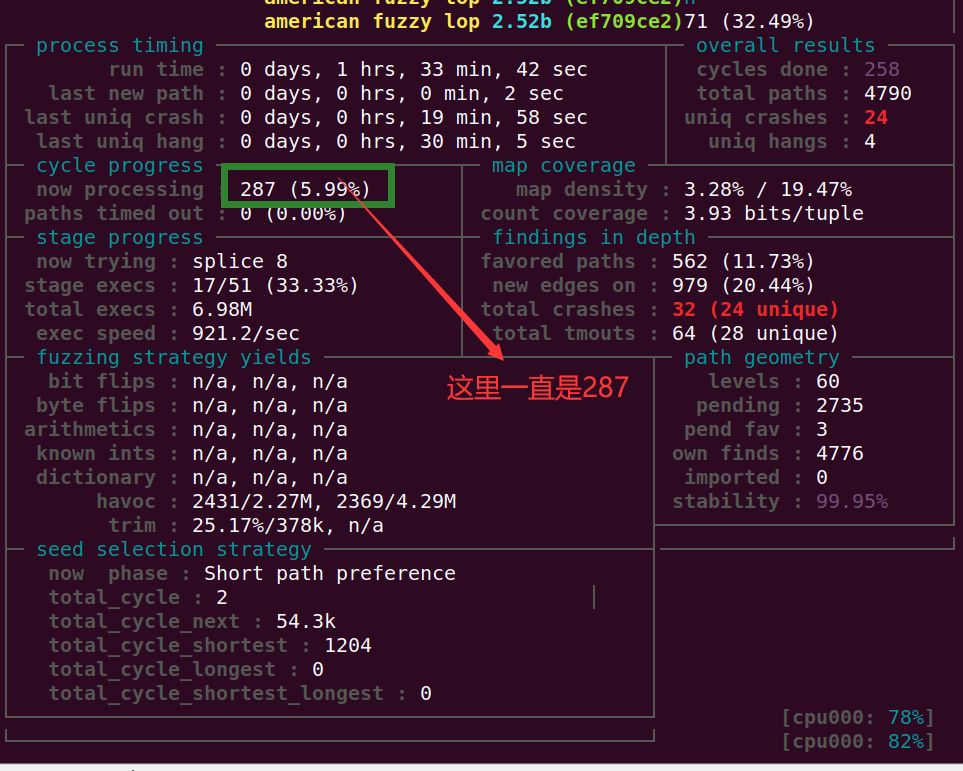
着重看一下select_shortest阶段到底除了啥问题
