CSAWCTF—FreeBSD gdb常用调试命令
没想到,上次更新是一年前了。到底是好是坏呢?
做下来最重要的感受,其实就是编程,很多时候你想的和程序体现出来的完全是两个东西。在程序细枝末节的地方浪费太多时间只能证明我的两个问题:
- 问题没想清,就开始编程,然后在做的过程中不断debug。这种方式吧,对于一些偏软件的程序可以。但是对于偏向于逻辑的,不行。
- 懒于编程,只要有可能用手算,就不编程,哪怕它再麻烦。人都是懒于思考的,我知道这很正常!但从长远来看,必须得强迫自己习惯编程,这样虽然开始难,但后续会变得简单,总之继续努力吧。
csawctf里面有个逆向题,food,是FreeBSD下面的一个二进制程序。为此安装了FreeBSD系统,但是呢,里面的gdb非常难用。包括但不限于:默认情况下不显示汇编、n\s好像没用必须要用ni。不知道是因为我长久不做了,很多指令忘了,还是FreeBSD里面的gdb就是傻逼。我把常用的总结起来,以后忘了也好找。
| 指令 | 作用 |
|---|---|
| display /16i $pc | 在每次单步调试的时候,显示的都是$pc往下的指令 |
| display /16i $pc-16 | 在每次单步调试的时候,显示一部分$pc上面的指令 |
| x/16i $pc | 显示的都是$pc往下的指令 |
| x/16i $pc-16 | 显示一部分$pc上面的指令 |
| x /54xw 0x12345678 | 显示内存地址0x12345678所存储的内容 。 x: 这是GDB的examine命令,用于查看内存中的数据54: 这表示要显示的数据的数量,也就是显示54个数据。x: 这表示以十六进制格式显示数据。 w: 这表示每个数据的大小为字(word),通常是4个字节。 |
| info registers | 查看寄存器 |
| info proc mappings | 查看进程信息,包括各种段地址,栈地址 |
| nexti–ni | 单步调试,对他是ni,难道不该是n? |
| set *((int*)) 0x12345678 = 0xdead | 将特定地址的内容修改为0xdead |
| b *0x123456 | 在0x123456地址处加上断点 |
| info break | 查看断点信息 |
| dump memory memory-dump.bin 0x123456789 0x223456789 | 将从起始地址0x123456789到终止地址0x223456789的内存空间中的数据转储为memory-dump.bin的二进制文件 |
警惕
1. memcpy(dest, “<”, 13988uLL);
这种第二个参数实际上是一个字符串指针!千万不要以为是<赋值了13988遍,这错误我犯了不知道多少遍了!
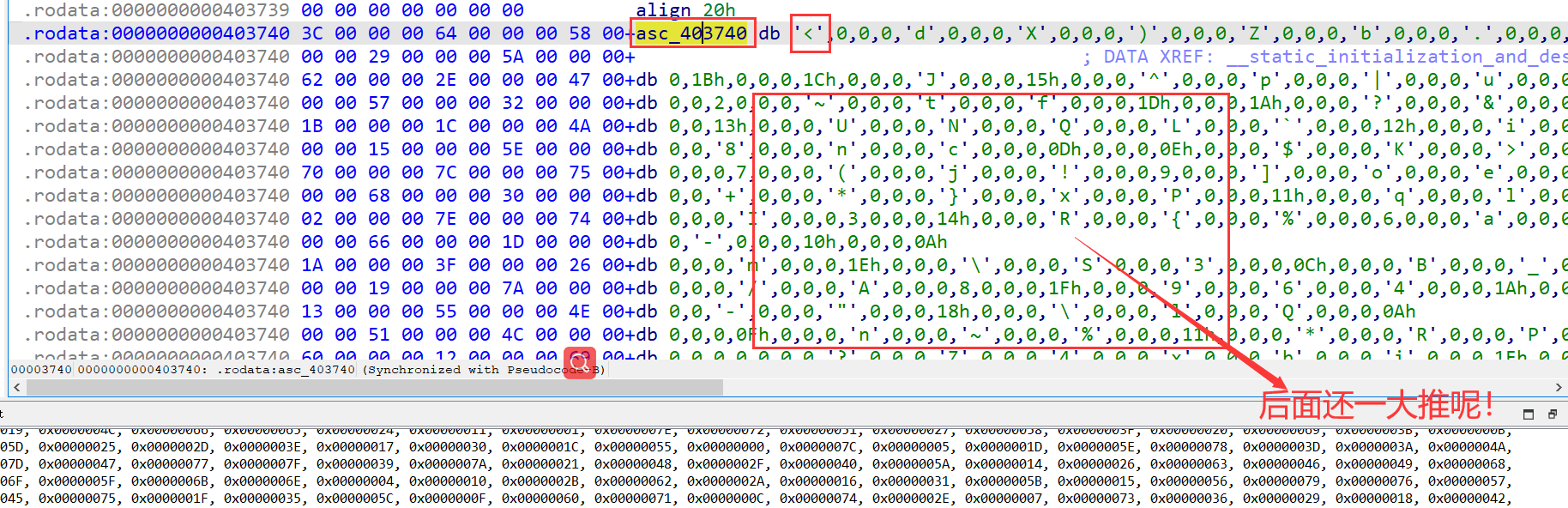
2. 右键可以直接转化为python list对象
别费劲dump下来然后再读文件了!
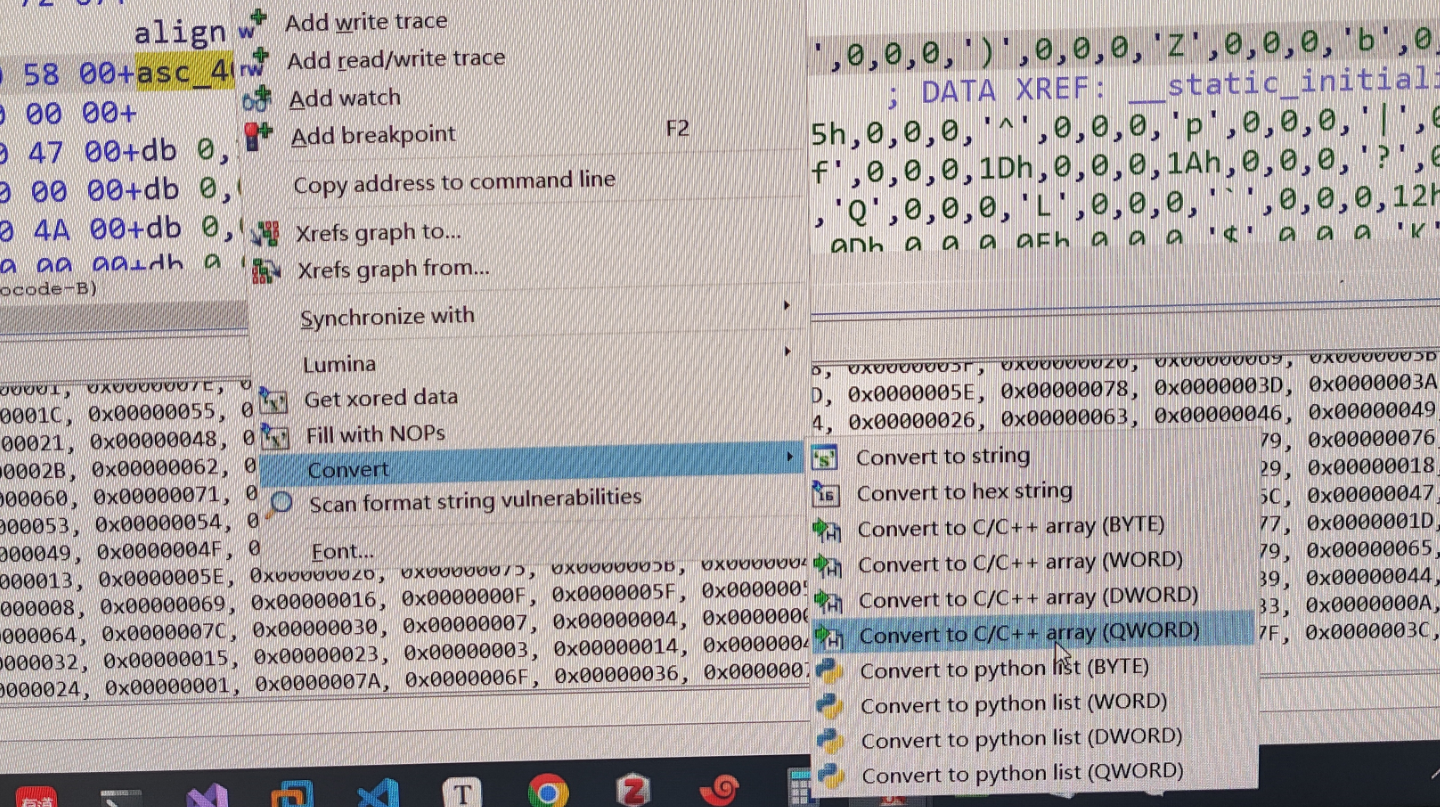
题目
其实是不难的一个异或题,但我做了2天半,是的,两天半。
csawctf{aN0ther_HeRRing_or_iS_tHis_iT}

EXPECTED_FLAG = "flag{ph3w...u finaLly g0t it! jump into cell wHen U g3t t0 the next cha11}"
SEED = [
0x3f,0x42,0x38,0x5F,0x7A,0x57,0x71,0x74,
0x66,0x44,0x47,0x32,0x3D,0x16,0x63,0x1F,
0x12,0x1A,0x12,0x5C,0x2A,0x3,0x64,0x1C,
0x15,0x40,0x1,0x3f,0x4c,0x2,0x3a,0x30,
0x1d,0x7c,0x69,0x4d,0x19,0x5f,0x48,0x5e,
0x20,0x3,0x17,0x9,0x52,0x06b,0x4c,0x65,
0x6f,0x48,0x6,0x5b,0x2b,0x28,0x40,0x2e,
0x4e,0x0b,0x16,0x31,0x30,0x56,0x21,0x6e,
0x2d,0x30,0x4b,0x1c,0x10,0x4,0x3f,0x18,
0x41,0x34
]
data = []
file = open('memory_dump.bin', 'rb')
file.seek(0x10)
for i in range(0,0x36b5//4):
byte_data = file.read(4)
if len(byte_data) == 4:
integer_value = int.from_bytes(byte_data, byteorder='little')
data.append(integer_value)
else:
print("Not enough bytes read")
def verify(flag):
for i in range(0,len(flag)):
SEED[i] = SEED[i] ^ flag[i]
for j in range(0,len(SEED)):
a = data[10*j+12]
b = a + flag[j%len(flag)]
SEED[j] = SEED[j] ^ data[b]
res = ""
for i in SEED:
res+=chr(i)
print(res)
for k in range(5,len(SEED)):
for m in range(0,300):
a = ((32*m)%256) ^ SEED[k]
b = int(SEED[k-5] == 'n')
SEED[k] = a ^ b
res = ""
for i in SEED:
res+=chr(i)
print(res)
return res == EXPECTED_FLAG
# flag = [ord(i) for i in "aN0ther_HeRRing_or_iS_tHis_iT"]
# print(verify(flag))
FLAG = [ord(i) for i in EXPECTED_FLAG]
for k in range(5,74):
for m in range(0,300):
a = ((32*m) ^ FLAG[k]) % 256
b = int(1 if FLAG[k - 5] == 'n' else 0)
FLAG[k] = a ^ b
print(FLAG)
SEED_1 = []
for i in range(0,len(SEED)):
SEED_1.append((FLAG[i] ^ SEED[i])%256)
print(len(SEED_1))
res = {}
res1 = {}
for index in range(0,74):
for i in range(32,127):
if (i ^ data[ data[10*index+12] + i])%256 == SEED_1[index]:
if index not in res:
res[index] = []
res[index].append(chr(i))
if data[data[10*index+12] + i] % 256 == SEED_1[index]:
if index not in res1:
res1[index] = []
res1[index].append(chr(i))
print(res)
print(res1)
# 确定最大的长度
for max_len in range(0,74):
if max_len not in res:
break
for str_len in range(1,max_len+1):
flag = ""
not_flag = False
for index in range(0,str_len):
if len(res[index]) == 1:
flag += res[index][0]
if (index+str_len) not in res1 or res[index][0] not in res1[index+str_len]:
# 没有解,或者不包含对应解 都排除
break
elif len(res[index]) > 1:
if index+str_len not in res1:
break
comman_element_list = [element for element in res[index] if element in res1[index+str_len]]
if len(comman_element_list) == 0:
not_flag = True
break
else:
flag += comman_element_list[0] # 任意挑一个就行,为了方便就直接选第一个了
if len(flag)==str_len and not not_flag:
print("csawctf{{{}}}".format(flag))
问题体现
第一个问题,不用说了,每次编程相信你都有体会。
第二个问题,就像这个逆向题中,我宁可一个一个对比,都不编程解决这个问题。跟结果失之交臂。我一直认为字符串的长度是30。因为我没看到前面的a。可问题不只有这一个原因,换一种展现形式,换程序解答,不仅我会对问题更加清楚,同时也方便我找到答案。