求职之路 — 学习总结
操作系统
1. 在进程切换的时候会发生什么?
在操作系统中,进程切换(也称为上下文切换)是指将 CPU 从一个进程切换到另一个进程的过程。这个过程由操作系统内核负责管理,并确保系统资源能够在多个进程之间公平和有效地分配。以下是进程切换过程中发生的一些关键步骤:
进程切换的主要步骤
- 保存当前进程的状态:
- CPU寄存器:当前进程的所有CPU寄存器(如程序计数器、堆栈指针、通用寄存器等)被保存到进程的控制块(Process Control Block,PCB)中。
- 内存管理信息:当前进程的内存管理信息(如页表或段表)也被保存。
- 更新进程状态:
- 当前进程的状态在其PCB中被标记为“等待”或“就绪”状态,以反映它不再占用CPU。
- 选择下一个进程:
- 操作系统的调度器选择下一个要运行的进程。选择算法可能是基于优先级、时间片轮转、最短剩余时间优先等调度策略。
- 恢复下一个进程的状态:
- CPU寄存器:从下一个进程的PCB中恢复所有的CPU寄存器。
- 内存管理信息:加载下一个进程的内存管理信息,以确保CPU能够正确访问进程的内存。
- 更新内存映射:
- 如果使用虚拟内存,操作系统可能需要更新内存映射(如页表)以确保CPU访问的是当前进程的内存。
- 更新进程状态:
- 被选中的进程状态在其PCB中被标记为“运行”状态,表示它正在占用CPU。
- 切换上下文:
最后一步,CPU的上下文被切换到新的进程,这包括跳转到新的程序计数器地址,并开始执行该进程的代码。
示例:进程切换的汇编代码
以下是一个简化的进程切换示例,以x86-64汇编代码展示了保存和恢复寄存器的基本步骤:
复制代码
; 保存当前进程的上下文
save_context:
; 保存通用寄存器
push rax
push rbx
push rcx
push rdx
push rsi
push rdi
push rbp
push r8
push r9
push r10
push r11
push r12
push r13
push r14
push r15
; 保存指令指针和标志寄存器
pushfq
mov [current_process_rsp], rsp ; 保存当前进程的堆栈指针
; 切换到下一个进程
mov rsp, [next_process_rsp] ; 恢复下一个进程的堆栈指针
; 恢复下一个进程的上下文
restore_context:
popfq
pop r15
pop r14
pop r13
pop r12
pop r11
pop r10
pop r9
pop r8
pop rbp
pop rdi
pop rsi
pop rdx
pop rcx
pop rbx
pop rax
ret ; 返回并继续执行下一个进程操作系统级别的进程切换
在实际操作系统中,进程切换涉及更多的复杂性,包括但不限于:
- 中断处理:中断(如时钟中断)通常是触发进程切换的事件。
- 内存保护和隔离:确保一个进程不能访问或修改另一个进程的内存。
- 多处理器支持:在多核系统中,可能需要处理多处理器间的同步和上下文切换。
总结
进程切换是操作系统中的一个关键机制,它允许多个进程共享CPU资源。通过保存当前进程的状态并恢复下一个进程的状态,操作系统确保了进程的正确执行。虽然在底层实现上涉及复杂的硬件和软件交互,但其基本概念是保存和恢复进程的CPU状态及其内存管理信息。
- 虚拟内存:
现代操作系统使用虚拟内存技术,为每个进程提供一个独立的虚拟地址空间。
虚拟地址空间通常包括代码段、数据段、堆段和堆栈段等。 - 页表:
每个进程都有自己的页表,用于映射虚拟地址到物理地址。
页表确保进程只能访问自己的虚拟地址空间,堆栈段也被映射到独立的物理内存区域。 - 内存管理单元 (MMU):
MMU 负责将虚拟地址转换为物理地址,并根据页表设置进行访问权限检查。
操作系统内核设置每个进程的页表,并通过 MMU 确保进程间的内存隔离。
+----------------------+ +----------------------+
| 进程 A 的虚拟内存空间 | | 进程 B 的虚拟内存空间 |
+----------------------+ +----------------------+
| | | |
| 代码段 (text) | | 代码段 (text) |
| | | |
+----------------------+ +----------------------+
| | | |
| 数据段 (data) | | 数据段 (data) |
| | | |
+----------------------+ +----------------------+
| | | |
| 堆段 (heap) | | 堆段 (heap) |
| | | |
+----------------------+ +----------------------+
| | | |
| 堆栈段 (stack) | | 堆栈段 (stack) |
| | | |
+----------------------+ +----------------------+
| 内核空间 | | 内核空间 |
+----------------------+ +----------------------+
进程 A 的页表 进程 B 的页表
+----------------------+ +----------------------+
| 代码段映射 | | 代码段映射 |
+----------------------+ +----------------------+
| 数据段映射 | | 数据段映射 |
+----------------------+ +----------------------+
| 堆段映射 | | 堆段映射 |
+----------------------+ +----------------------+
| 堆栈段映射 | | 堆栈段映射 |
+----------------------+ +----------------------+
| 内核空间映射 | | 内核空间映射 |
+----------------------+ +----------------------+
进程 A 的上下文 进程 B 的上下文
+----------------------+ +----------------------+
| 寄存器值 | | 寄存器值 |
| RSP -> 堆栈指针 | | RSP -> 堆栈指针 |
| RIP -> 指令指针 | | RIP -> 指令指针 |
+----------------------+ +----------------------+
| 页表基地址 | | 页表基地址 |
+----------------------+ +----------------------+
2. 页表
页表是存储在内存中的。页表是虚拟内存管理的一个关键组件,用于将虚拟地址映射到物理地址。操作系统和硬件协同工作,通过内存管理单元(MMU)使用页表来执行地址转换和内存保护。
页表的结构
页表通常是多级结构,以减少内存消耗并提高查找效率。以下是典型的 x86-64 架构的四级页表结构:
- 页全局目录 (PGD):
- 最上级页表,包含指向页上级目录的指针。
- 页上级目录 (PUD):
- 第二级页表,包含指向页中间目录的指针。
- 页中间目录 (PMD):
- 第三级页表,包含指向页表的指针。
- 页表 (PT):
- 最低级页表,包含指向实际物理页的指针。
每一级页表都包含页表项(PTE),每个页表项都指向下一级页表或实际物理内存页。
页表的存储和访问
页表本身存储在内存中。当进程运行时,CPU 使用内存管理单元(MMU)和控制寄存器来访问页表并进行地址转换。
CPU 寄存器
- CR3 寄存器:在 x86-64 架构中,CR3 寄存器包含当前活动页表(通常是页全局目录)的物理地址。当进行上下文切换时,操作系统会更新 CR3 寄存器以指向新进程的页表。
地址转换过程
- 虚拟地址分解:虚拟地址分为多个部分,每个部分对应于页表结构中的不同级别。
- 查找页表项:MMU 使用虚拟地址的各个部分逐级查找页表项,从 PGD 开始,直到找到最终的物理页地址。
- 访问物理内存:根据最终找到的物理页地址,访问实际的物理内存。
示例:四级页表地址转换
假设虚拟地址为 0x123456789ABC:
- 虚拟地址分解:
- PGD 索引:0x1
- PUD 索引:0x2
- PMD 索引:0x3
- PT 索引:0x4
- 页内偏移:0x56789ABC
- 地址转换:
- 从 CR3 寄存器中获取 PGD 基地址。
- 使用 PGD 索引查找 PUD 的基地址。
- 使用 PUD 索引查找 PMD 的基地址。
- 使用 PMD 索引查找 PT 的基地址。
- 使用 PT 索引查找物理页的基地址。
- 加上页内偏移,得到最终的物理地址。
+-----------------------+
| CR3 寄存器 |
| (PGD 基地址) |
+-----------+-----------+
|
v
+-----------------------+ +-----------------------+
| 页全局目录 (PGD) | | 页表项 (PTE) |
| +------+ +----------+ | | +------+ +----------+ |
| | 索引 | | PUD 基地址| | | | 索引 | | 物理页地址 | |
| +------+ +----------+ | | +------+ +----------+ |
+-----------------------+ +-----------------------+
|
v
+-----------------------+
| 页上级目录 (PUD) |
| +------+ +----------+ |
| | 索引 | | PMD 基地址| |
| +------+ +----------+ |
+-----------------------+
|
v
+-----------------------+
| 页中间目录 (PMD) |
| +------+ +----------+ |
| | 索引 | | PT 基地址 | |
| +------+ +----------+ |
+-----------------------+
|
v
+-----------------------+
| 页表 (PT) |
| +------+ +----------+ |
| | 索引 | | 物理页地址 | |
| +------+ +----------+ |
+-----------------------+
|
v
+-----------------------+
| 物理页 |
| +-------------------+ |
| | 页内偏移 | |
| +-------------------+ |
+-----------------------+
3. 虚拟内存和物理内存的关系
程序的堆栈段、代码段、数据段等最终都映射到物理内存上。虚拟内存管理通过页表将进程的虚拟地址空间映射到实际的物理内存地址,从而实现进程对内存的访问。
虚拟内存是操作系统提供的一种抽象,使每个进程看起来拥有独立的、连续的内存地址空间。实际上,这些虚拟地址通过页表映射到物理内存中的不同位置。
虚拟内存的分段
典型的进程虚拟地址空间包括以下几个主要段:
- 代码段 (text segment):
- 存储程序的可执行代码。
- 映射到物理内存中的只读区域,通常由操作系统和加载器负责加载。
- 数据段 (data segment):
- 存储全局变量和静态变量。
- 包括已初始化数据段和未初始化数据段(BSS)。
- 堆段 (heap segment):
- 用于动态内存分配,例如通过 malloc 等函数。
- 堆段的大小可以在程序运行时动态增长。
- 堆栈段 (stack segment):
- 用于函数调用和局部变量。
- 堆栈从高地址向低地址增长。
每个进程有自己的页表,操作系统通过页表管理虚拟地址到物理地址的映射
页表 (Page Table):
- 页表是存储在物理内存中的数据结构,每个进程有自己独立的页表。
- 页表条目(PTE)包含虚拟页面和物理页面的映射信息,包括页的物理地址和访问权限。
进程的虚拟地址空间 物理内存
+----------------------+ +----------------------+
| 高地址 | | |
| ... | | |
| 堆栈段 (stack) | | 物理页 |
| ... | | ... |
| | | ... |
| 堆段 (heap) | | |
| ... | | 物理页 |
| | | |
| 数据段 (data) | | 物理页 |
| | | |
| 代码段 (text) | | 物理页 |
| | | |
| 低地址 | | |
+----------------------+ +----------------------+
虚拟地址空间 页表 物理内存
+-------------------+ +-------------+ +-----------------+
| | | 页表项 (PTE) | | 物理页框 (PF) |
| 代码段 (text) | | +---------+ | | +-------------+ |
| +0x0000 | --+--------> | | 物理地址 | | +-------> | | 代码段 | |
| | | | +---------+ | | | +-------------+ |
+-------------------+ | +-------------+ | +-----------------+
| | | |
| 数据段 (data) | | +-------------+ | +-----------------+
| +0x1000 | --+--------> | 页表项 (PTE) | +-------> | 物理页框 (PF) |
| | | +---------+ | | +-------------+ |
+-------------------+ | | 物理地址 | | | | 数据段 | |
| | | +---------+ | | +-------------+ |
| 堆段 (heap) | +-------------+ +-----------------+
| +0x2000 | |
| | | +-----------------+
+-------------------+ +-------------+ | | 物理页框 (PF) |
| | | 页表项 (PTE) | | | +-------------+ |
| 堆栈段 (stack) | --+--------> | +---------+ | +------>+------>| | 堆栈段 | |
| +0x3000 | | | | 物理地址 | | | +-------------+ |
| | | | +---------+ | +-----------------+
| | | +-------------+
+-------------------+ |
|
+-------------------+ |
| 页表基地址 | |
| +-------------+ | |
| | CR3 | | --+
| +-------------+ |
+-------------------+
4. 银行家调度算法
(https://www.cnblogs.com/wkfvawl/p/11929508.html)[https://www.cnblogs.com/wkfvawl/p/11929508.html]
(1)系统在某一时刻的安全状态可能不唯一,但这不影响对系统安全性的判断。
(2)安全状态是非死锁状态,而不安全状态并不一定是死锁状态。即系统处于安全状态一定可以避免死锁,而系统处于不安全状态则仅仅可能进入死锁状态。
做题的时候,列好3个矩阵。max矩阵即进程最大需要的资源矩阵,allocation矩阵即已经分配给进程的资源矩阵,need矩阵进程目前还需要的资源矩阵。available即目前还拥有的资源数量。然后就是假设分配给某个进程资源后,是否存在一个安全序列。如果存在,则系统安全。不存在,则系统 可能死锁。
5. 乐观锁和悲观锁
乐观锁和悲观锁是两种常见的并发控制机制,用于解决多线程或多进程环境下的资源竞争问题。它们在处理并发事务时的理念和实现方式有所不同。
- 悲观锁(Pessimistic Lock)
悲观锁 的核心思想是对资源的并发访问持悲观态度,假设每次数据访问都会发生冲突,因此在操作数据前,必须先加锁,以防止其他事务对该数据进行修改。
特点:
- 锁定资源: 在读取或修改数据之前,对数据加锁,确保其他事务在当前事务完成之前无法访问或修改该数据。
- 实现方式: 通常通过数据库的行锁、表锁或分布式锁来实现。对于数据库操作,悲观锁的典型实现是 SELECT FOR UPDATE,这会在查询数据的同时对查询的行加上排他锁。
- 适用场景: 适用于数据争用非常激烈的场景,如同一份数据被多个事务频繁修改,锁可以避免脏读、不可重复读、幻读等问题。
缺点:
- 性能影响: 因为每次操作都要加锁和释放锁,可能会导致较高的性能开销,尤其是在锁定范围大、锁定时间长的情况下。
可能产生死锁: 如果多个事务之间的锁定顺序不当,可能会发生死锁。
- 乐观锁(Optimistic Lock)
乐观锁 的核心思想是对资源的并发访问持乐观态度,假设大部分情况下不会发生冲突,因此在修改数据时不加锁,但在提交修改时会进行冲突检测。
特点:
- 无锁操作: 在读取数据时不加锁,允许其他事务并发修改数据,只有在提交时才进行冲突检测。
- 实现方式: 通常通过版本号(Version)或时间戳来实现。每次读取数据时获取当前版本号或时间戳,更新时再比较。如果提交时版本号或时间戳未发生变化,说明没有其他事务修改过数据,可以提交修改;否则,操作会失败,需要重新读取数据并尝试更新。
- 适用场景: 适用于数据争用不严重的场景,如大多数事务对同一份数据的修改概率较低的情况下,乐观锁的性能较高。
缺点:
- 处理冲突的成本: 如果事务冲突频繁,乐观锁可能导致大量重试操作,影响系统性能。
- 需要业务支持: 乐观锁通常需要业务逻辑配合,如设计表结构时引入版本号字段。
总结对比
- 锁定策略:
- 悲观锁:假定会发生冲突,主动加锁防止其他事务修改数据。
- 乐观锁:假定不会发生冲突,不加锁,但在提交时检测冲突。
- 适用场景:
- 悲观锁:适用于并发写入频繁、数据冲突概率高的场景。
- 乐观锁:适用于并发写入较少、冲突概率低的场景。
- 性能影响:
- 悲观锁:可能带来较高的性能开销,尤其在高并发环境中。
- 乐观锁:在冲突较少的情况下性能更优,但在冲突频繁时重试会带来额外开销。
6. 系统调用与一般调用之间的区别
系统调用(system call)与一般函数调用(function call)在计算机系统中有着不同的作用和执行方式。以下是它们的主要区别:
1. 定义与作用
- 系统调用:
- 定义:系统调用是操作系统提供的接口,通过它,用户程序可以请求操作系统执行特定的服务,例如文件操作、进程管理、内存分配、网络通信等。
- 作用:系统调用使得用户空间的程序可以访问和使用操作系统内核提供的资源和服务,例如读取文件、发送网络请求、分配内存等。
- 一般调用:
- 定义:一般函数调用是在程序内部或库中调用函数,不涉及操作系统内核,只在用户空间中执行。
- 作用:一般函数调用主要用于程序内部的逻辑处理和功能实现,比如数学计算、字符串操作、数据处理等。
2. 执行环境
- 系统调用:
- 执行环境:系统调用需要从用户空间切换到内核空间执行。用户程序通过系统调用将请求传递给操作系统内核,操作系统内核在内核态下执行这些操作。
- 权限级别:系统调用执行在更高权限的内核态(Ring 0)下,因为它需要访问硬件资源和操作系统核心功能。
- 一般调用:
- 执行环境:一般函数调用在用户空间执行,不涉及操作系统内核,不需要进行用户态到内核态的切换。
- 权限级别:一般函数调用在用户态(Ring 3)下执行,只能访问用户空间的资源。
3. 开销
- 系统调用:
- 开销:由于系统调用涉及从用户态到内核态的切换,这种上下文切换需要一定的时间和资源,因此系统调用的开销较大。
- 原因:切换过程需要保存当前用户态的状态,进入内核态后执行操作,再切换回用户态,恢复状态。这一过程增加了执行时间。
- 一般调用:
- 开销:一般函数调用在同一执行上下文中进行,不涉及上下文切换,开销较小。
- 原因:函数调用只需要在当前栈上保存状态(如函数参数、返回地址),然后跳转到函数的执行代码,执行完毕后返回即可。
4. 使用场景
- 系统调用:
- 使用场景:系统调用用于需要操作系统服务或资源的场景,如文件读写、进程创建与管理、网络通信等。
- 示例:
read(),write(),fork(),execve(),open(),close()等。
- 一般调用:
- 使用场景:一般函数调用用于普通的程序逻辑处理,不涉及系统级资源管理。
- 示例:
strlen(),printf(),sort(),math.sqrt()等。
5. 错误处理
- 系统调用:
- 错误处理:系统调用由于涉及硬件资源和操作系统服务,可能出现各种系统级错误,通常通过返回负值或设置
errno来表示错误,需要特殊处理。
- 错误处理:系统调用由于涉及硬件资源和操作系统服务,可能出现各种系统级错误,通常通过返回负值或设置
- 一般调用:
- 错误处理:一般函数调用的错误通常是程序逻辑错误或输入错误,处理方式多样,视具体情况而定。
总结
- 系统调用 是用户程序与操作系统之间的接口,用于请求操作系统服务,涉及用户态到内核态的切换,开销较大,但允许访问和操作系统资源。
- 一般函数调用 仅在用户空间执行,用于程序内部的逻辑处理和功能实现,开销较小,不涉及操作系统内核。
理解系统调用和一般函数调用的区别,有助于开发者更好地优化程序性能,并正确选择和使用操作系统提供的服务。
系统调用可以嵌套,但需要理解嵌套调用的具体含义和实际情况。
1. 嵌套系统调用的概念
嵌套系统调用指的是在一个系统调用的执行过程中,另一个系统调用被调用。例如,系统调用 A 在执行过程中,又触发了系统调用 B。
2. 实际情况
- 内核态的嵌套:
- 在某些复杂的操作中,操作系统内核本身可能在执行一个系统调用时,需要调用其他内核功能,这可能会触发其他系统调用。虽然从用户程序的角度看,这些调用是独立的,但内核可能会嵌套地执行它们。例如,在文件系统的实现中,打开文件(
open())的系统调用可能会在内核态触发其他与文件系统相关的系统调用。
- 在某些复杂的操作中,操作系统内核本身可能在执行一个系统调用时,需要调用其他内核功能,这可能会触发其他系统调用。虽然从用户程序的角度看,这些调用是独立的,但内核可能会嵌套地执行它们。例如,在文件系统的实现中,打开文件(
- 用户态到内核态的嵌套:
- 在典型的操作系统设计中,用户态程序可以多次调用系统调用,而这些调用可能看起来是嵌套的。但从内核的角度看,每次调用都是一个独立的上下文切换,即从用户态切换到内核态,完成调用后再返回用户态。因此,虽然用户程序中可能出现看似嵌套的系统调用,但它们在内核中通常是依次处理的。
3. 嵌套调用的处理方式
- 上下文切换:每次系统调用都会导致从用户态到内核态的上下文切换,即使是在一个系统调用内部调用另一个系统调用,这个过程也需要重新保存和恢复上下文。操作系统内核是设计来处理这样的场景的。
- 重入与线程安全:大多数现代操作系统内核是重入的,这意味着多个系统调用可以同时在不同的上下文(例如不同的线程或进程)中执行,即使它们是嵌套调用。内核通过锁、原子操作等机制来确保这些调用的线程安全。
4. 示例
- 实际示例:假设你在用户程序中执行
write()系统调用,这个调用会在内核中进行文件写操作。如果这个文件是网络文件系统上的一个文件,那么在write()的过程中,内核可能会进行网络数据传输,这可能需要调用另一个与网络栈相关的系统调用。
7. 为什么页号最多占一页的容量
如果页表的大小超过了一页的容量,则无法通过一个页表索引直接访问完整的页表,这会导致分页机制失去简洁性和有效性。在这种情况下,内存管理变得复杂,页表需要额外的管理机制来处理其超过一页容量的部分,这样会降低分页系统的效率。
因此,页号对应的页表最多只能占一页的容量,这是为了确保分页系统的页表能够被有效地管理和分配。如果页表超过一页的容量,可能需要更复杂的多级页表或其他机制来处理,这违背了分页简化内存管理的初衷。
8.
计算机网络
1. 跨域的问题是出于浏览器的同源策略限制
跨域问题主要是由于浏览器的同源策略(Same-Origin Policy, SOP)导致的。同源策略是一种重要的安全机制,用来防止恶意网站通过脚本对另一个网站的数据进行未经授权的访问。
什么是同源策略?
同源策略规定,只有当两个 URL 具有相同的协议、域名和端口号时,它们才被认为是同源的。具体来说,同源策略的三要素是:
- 协议:如 HTTP、HTTPS。
- 域名:如 example.com。
- 端口号:如 80(HTTP 默认端口)或 443(HTTPS 默认端口)。
如果两个 URL 的协议、域名和端口号都相同,它们就是同源的,否则就是跨域的。
跨域问题的表现
当 Web 应用程序尝试从一个不同源的服务器请求资源时,浏览器会阻止这些请求,表现为跨域问题。例如,来自 https://example.com 的网页试图通过 JavaScript 发起一个到 https://api.anotherdomain.com 的请求,就会因为同源策略而被阻止。
常见的跨域操作包括:
- AJAX 请求:使用 XMLHttpRequest 或 fetch API 向不同源的服务器发起请求。
- 嵌入第三方资源:如在页面中嵌入来自不同源的
<iframe>、图片、脚本等。 - 访问第三方的 cookies、localStorage 等。
解决跨域问题的方法
由于跨域问题是由同源策略引起的,因此解决跨域问题的核心是让浏览器信任不同源的请求。常见的解决方案包括:
- CORS(Cross-Origin Resource Sharing):
CORS 是一种机制,允许服务器通过设置特定的 HTTP 头,来告诉浏览器允许来自其他源的请求。常见的 CORS 头包括:- Access-Control-Allow-Origin: 指定允许访问资源的域名,可以是 * 表示允许所有域名访问。
- Access-Control-Allow-Methods: 指定允许的 HTTP 方法,如 GET、POST 等。
- Access-Control-Allow-Headers: 指定允许的 HTTP 请求头。
- JSONP(JSON with Padding):
JSONP 是一种跨域请求的早期解决方案,通常用于 GET 请求。它通过动态创建一个<script>标签,并将请求参数放在 URL 中。由于<script>标签不受同源策略的限制,因此可以绕过跨域问题。不过,JSONP 仅支持 GET 请求,且存在安全性问题,因此不推荐用于现代应用。 - 代理服务器:
可以通过在同源服务器上设置代理,将跨域请求转发到目标服务器。客户端向同源服务器发送请求,服务器再代为请求目标资源。这种方式能够很好地绕过浏览器的同源策略,但需要额外配置服务器。 - 服务器端渲染:
对于某些请求,可以在服务器端完成所有数据请求,并将结果直接渲染给客户端,从而避免浏览器端的跨域问题。
总结
跨域问题源于浏览器的同源策略,旨在保护用户免受跨站点脚本攻击。通过使用 CORS、JSONP、代理服务器等技术,可以解决跨域问题,允许安全的跨域数据访问。
只要不通过浏览器访问,就不会触发同源策略?
同源策略(Same-Origin Policy, SOP) 是一种专门针对浏览器的安全机制。因此,只有在通过浏览器进行访问时,同源策略才会生效,限制跨源请求。如果不通过浏览器访问,比如服务器端脚本、命令行工具、移动应用、后端服务之间的通信等,则不受同源策略的限制。
具体来说:
- 浏览器访问:
- 当你在浏览器中访问网页,并且该网页中的脚本尝试从不同源获取资源时,浏览器的同源策略会生效,限制这些跨域请求。
- 例如,使用 JavaScript 发起 AJAX 请求、嵌入跨域的
<iframe>、通过 JavaScript 访问 cookies 等,都会受到同源策略的限制。
非浏览器环境:
- 服务器端代码:如在服务器端的 Python、Node.js、Java、PHP 等编程语言中发起的 HTTP 请求,不受同源策略的限制。服务器可以自由地与任何源通信,无需考虑同源策略。
- 命令行工具:如 curl、wget 等工具可以用来发起 HTTP 请求,不受同源策略限制。
- 移动应用:移动应用在请求 API 或资源时,也不受同源策略的限制,应用开发者可以自由地与不同源的服务器进行通信。
举个例子:
- 浏览器环境:你在 https://example.com 上运行的 JavaScript 代码尝试向 https://api.anotherdomain.com 发起 AJAX 请求。由于不同源,浏览器的同源策略会阻止这个请求,除非目标服务器通过 CORS 头允许该请求。
- 服务器环境:假设你在服务器端(如 Node.js)写了一段代码,通过 https.request 向 https://api.anotherdomain.com 发起请求。这时,这个请求不会受到同源策略的限制,可以直接进行。
- 服务器通过其他安全措施来保护资源和数据的安全,例如身份验证、授权机制、防火墙等。服务器端的安全依赖于开发者对访问控制和数据保护的管理,而不是依赖于同源策略。
总结
同源策略只在浏览器环境中生效,用来保护用户的数据安全,防止跨站脚本攻击。而在非浏览器环境中,如服务器端代码、命令行工具、移动应用等,同源策略不适用,可以自由地发起跨源请求。因此,如果你的应用不涉及浏览器访问,就不需要考虑同源策略的限制。
2. 数据链路层中,哪种方法可以用于差错检测
- 奇偶检验(Parity Check)
- 循环冗余校验(Cyclic Redundancy Check, CRC)
- 校验和(CheckSum)
- 汉明码(Hamming Code)
3. 跨域的解决方案,Nginx反向代理
正向代理是你正在用的VPN模式,即客户端通过代理访问服务器。
反向代理是代理服务器,也就是客户端所有的请求都会发送到Nginx服务器上,再由Nginx服务器对过来的请求进行分发。此时,所有的请求都将是同域的,因为所请求的协议+ip+端口Nginx配置的。
server {
listen 9001;
server_name 192.168.17.129;
location ~ /edu/ {
proxy_pass http://127.0.0.1:8080
}
location ~ /vod/ {
proxy_pass http://127.0.0.1:8081
}
}4. http的状态码有哪些
HTTP 状态码分为 5 类,用来表示服务器响应的不同状态。这些状态码帮助客户端了解服务器的响应结果。以下是 HTTP 状态码的分类及常见的状态码:
1xx:信息性响应
表示请求已接收,服务器正在处理。
- 100 Continue:请求部分已成功,客户端可以继续请求。
- 101 Switching Protocols:服务器同意切换协议。
- 102 Processing:服务器已收到并正在处理请求,但没有响应可用。
2xx:成功
表示请求已成功被服务器接收、理解并处理。
- 200 OK:请求成功,响应的具体内容由方法决定(如GET请求返回资源,POST请求返回结果)。
- 201 Created:请求成功并导致了资源的创建。
- 202 Accepted:请求已被接受,但尚未处理完。
- 203 Non-Authoritative Information:请求成功,但返回的信息不是来自原始服务器,而是经过第三方。
- 204 No Content:请求成功,但不返回任何内容(如删除资源操作)。
- 205 Reset Content:请求成功,请求者应重置视图。
- 206 Partial Content:服务器仅返回了部分资源内容(常用于断点续传或多部分下载)。
3xx:重定向
表示客户端需要进一步操作才能完成请求。
- 300 Multiple Choices:请求有多个可选的响应,客户端可以选择。
- 301 Moved Permanently:请求的资源已被永久移动到新位置。
- 302 Found:临时重定向,请求的资源临时位于其他位置。
- 303 See Other:请求的资源可以在另一 URI 获取,建议使用 GET 访问。
- 304 Not Modified:资源未修改,客户端可以使用缓存副本。
- 307 Temporary Redirect:资源临时重定向,客户端应该继续使用原来的请求方法。
- 308 Permanent Redirect:资源已永久移动,和 301 类似,但客户端必须使用原请求方法。
4xx:客户端错误
表示请求有错误,服务器无法处理。
- 400 Bad Request:请求有语法问题,服务器无法理解。
- 401 Unauthorized:请求未经授权,客户端需要提供认证。
- 403 Forbidden:服务器理解请求,但拒绝执行。
- 404 Not Found:服务器找不到请求的资源。
- 405 Method Not Allowed:请求方法不被允许(如用 POST 请求一个只能 GET 的资源)。
- 406 Not Acceptable:请求的内容特性不符合客户端的请求。
- 408 Request Timeout:请求超时,服务器等待客户端发送请求时间过长。
- 409 Conflict:请求与资源的当前状态发生冲突。
- 410 Gone:请求的资源已被永久删除,且没有转发地址。
- 411 Length Required:请求缺少
Content-Length头,服务器拒绝接受没有指定长度的请求。 - 413 Payload Too Large:请求实体过大,服务器无法处理。
- 414 URI Too Long:请求的 URI 过长,服务器无法处理。
- 415 Unsupported Media Type:服务器不支持请求的媒体格式。
- 429 Too Many Requests:客户端发送了太多请求,被限制。
5xx:服务器错误
表示服务器在处理请求时出现了错误。
- 500 Internal Server Error:服务器遇到未预料的情况,无法完成请求。
- 501 Not Implemented:服务器不支持请求的方法或功能。
- 502 Bad Gateway:网关或代理服务器从上游服务器收到无效响应。
- 503 Service Unavailable:服务器目前无法处理请求(超负载或维护)。
- 504 Gateway Timeout:网关或代理服务器未能及时从上游服务器获取响应。
- 505 HTTP Version Not Supported:服务器不支持请求使用的 HTTP 协议版本。
每个状态码都由三位数字组成,第一位数字标识了状态的类别,后两位提供了具体的状态信息。
5. UDP具体的使用场景
UDP(User Datagram Protocol)是一种无连接、轻量级的传输层协议,常用于对速度和效率要求较高、但不需要严格保证数据可靠性的应用。以下是 UDP 的具体使用场景:
1. 实时 通信
UDP 非常适合用于需要低延迟的实时通信场景,在这些应用中,丢失一些数据包不会影响整体的用户体验。常见的应用包括:
- VoIP(Voice over IP):语音通话,例如 Skype、Zoom。实时语音传输需要低延迟,即使少量语音数据丢失也不会明显影响对话。
- 视频通话:视频通话也对延迟敏感,少量的丢包或抖动不会严重影响用户体验。
2. 实时视频流传输
在视频流媒体传输中,例如在线直播、IPTV、游戏直播等,实时性至关重要。UDP 可以快速传输视频帧,而不会像 TCP 那样因为丢包导致整体传输延迟。典型的协议有:
- RTSP(Real-Time Streaming Protocol):常用于实时视频流传输,底层通常使用 UDP 来减少延迟。
- RTP(Real-Time Transport Protocol):视频和音频流媒体传输协议,通常使用 UDP 来实现低延迟传输。
3. 在线游戏
- 在多人在线游戏中,快速响应比数据完整性更重要。UDP 能够提供低延迟的通信,游戏服务器可以周期性地发送更新(如玩家的位置、状态等)。即使丢失某些数据包,游戏客户端也能通过后续的更新恢复正常状态。例如:
- 射击游戏(FPS)
- 竞技类游戏(MOBA)
- 这些游戏中,掉帧或者丢失少量状态信息不会影响游戏进程,UDP 的传输效率更能满足快速更新的需求。
4. 广播和多播
UDP 支持多播(Multicast)和广播(Broadcast),非常适合应用在需要同时向多个终端发送相同数据的场景,例如:
- IPTV:通过多播向多个用户发送电视信号流。
- 局域网内的服务发现:设备在局域网内通过广播发送查询请求,如常见的 DHCP、UPnP 等协议使用 UDP 来在局域网内快速发现可用服务。
- 在线教学:教师向多个学生广播数据流(如音视频)。
5. DNS 查询
- DNS(Domain Name System):互联网中的域名解析通常使用 UDP 进行 DNS 查询,因为大多数查询和响应的数据量较小,使用 UDP 可以降低延迟。对于超过 512 字节的查询,DNS 可以使用 TCP,但通常的域名解析都是通过 UDP 实现的。
6. 简单的请求-响应协议
- 例如 TFTP(Trivial File Transfer Protocol),是一种简单的文件传输协议,常用于网络设备的固件升级、系统配置文件传输等。它的实现基于 UDP,牺牲了一些可靠性来提升传输效率。
7. 物联网(IoT)设备通信
- 物联网设备通常受限于网络带宽、计算能力和电源限制。UDP 协议可以通过减少开销来提高传输效率。某些轻量级的通信协议,如 CoAP(Constrained Application Protocol),使用 UDP 来提供低资源占用的通信方式,常用于传感器、嵌入式设备等物联网设备的通信。
8. 局域网(LAN)通信
- 在局域网内传输数据时,由于网络环境较为可靠,UDP 可以实现高速的数据交换。例如局域网内的文件共享、打印机的状态更新等,UDP 可以减少传输延迟和开销。
9. DHCP(动态主机配置协议)
- DHCP(Dynamic Host Configuration Protocol) 通过 UDP 协议向网络设备分配 IP 地址。DHCP 使用 UDP 是因为它需要通过广播方式找到网络中的设备,并与它们交换数据,而 TCP 的连接建立方式不适合这种应用场景。
10. SNMP(简单网络管理协议)
- SNMP(Simple Network Management Protocol) 是网络管理中常用的协议,通常使用 UDP 作为传输层协议。SNMP 需要快速地获取网络设备的状态或进行配置更新,因此 UDP 的轻量特性很适合这种快速、低开销的操作。
总结
UDP 的特点是 无连接、低延迟、低开销,但它不提供可靠性保证,因此适合需要实时性或广播、多播传输的场景。典型的应用场景包括 实时通信(如语音、视频通话)、在线游戏、视频流、物联网等。UDP 的设计使其能够快速传输数据,即使在丢包情况下,也不会像 TCP 那样影响整体传输速度,因此它广泛用于对数据完整性要求较低、但对速度和实时性要求较高的网络通信中。
6. http为什么是无状态的,说说你的理解
HTTP(Hypertext Transfer Protocol)被称为无状态协议,这意味着它在每次请求之间不会保留任何关于客户端的状态。服务器和客户端之间的每个请求都是独立的,与之前或之后的请求无关。
我的理解:
- 无状态的本质: 每个 HTTP 请求都是独立的事务,服务器在处理每个请求时,不会自动记住之前发生的任何事情。换句话说,服务器不会记住用户在上一个请求中提交了什么数据,也不会跟踪会话信息。
- 为什么 HTTP 是无状态的?
- 简化设计:无状态协议的设计更简单,不需要服务器维护大量的会话数据,这大大简化了服务器的实现。
- 更好的扩展性:由于服务器不需要保存每个客户端的状态,多个服务器可以在集群中分布式处理请求,提升扩展性。这使得 HTTP 特别适合于互联网的大规模应用。
- 灵活性:每个请求可以被不同的服务器处理,客户端和服务器之间的连接是短暂的。它允许通过代理、缓存等方式更高效地分发和处理请求。
- 无状态的挑战与解决方案:
- 状态管理的需求:尽管 HTTP 是无状态的,但很多 web 应用(如购物车、登录会话等)需要管理用户的状态。为了解决这个问题,引入了 cookie、session、token 等机制。这些机制使得服务器和客户端能够在多个请求之间共享状态信息。
- Cookie:服务器通过在响应中发送一个
Set-Cookie头,将状态信息存储在客户端浏览器中,客户端在后续的请求中会自动带上这个 cookie,服务器可以通过它识别客户端。 - Session:服务器可以在每次请求后生成一个唯一的会话标识符(如
session_id),并通过cookie或URL将它传递给客户端。客户端每次请求时会带上这个 ID,服务器就可以通过它来恢复客户端的状态。 - Token:常见于 REST API 和现代认证机制(如 JWT)。服务器通过签发一个加密的 token,客户端会在后续的请求中通过 HTTP 头(如
Authorization)传递 token,服务器通过解密这个 token 获取用户状态。
实际场景下的无状态:
- 每次访问网页或资源时,浏览器会发送一个请求到服务器。服务器处理完请求后,返回响应,然后结束与客户端的交互。下次用户再访问同一个页面时,服务器不会“记住”之前访问的内容,必须依赖客户端发送的信息,如 cookie 或 session ID,来保持一些持久化的状态。
- 例如,用户打开一个电商网站,向购物车中添加商品时,服务器并不会自动记住用户之前的商品添加情况。购物车的状态需要依赖某种机制(如 session 或 cookie)来管理。
小结:
HTTP 无状态的设计让它能够在网络上实现更简洁、灵活、扩展性强的通信模型,但为了满足实际应用中状态管理的需求,使用了 cookie、session、token 等机制来弥补这一特性。
数据结构
1. KMP算法
2. 二叉排序树
二叉排序树(Binary Search Tree, BST),也称为二叉查找树,是一种特殊的二叉树结构,它具有以下性质:
二叉排序树的性质
- 节点的左子树:对于树中的任意一个节点,其左子树中所有节点的值都小于该节点的值。
- 节点的右子树:对于树中的任意一个节点,其右子树中所有节点的值都大于该节点的值。
- 每个子树都是二叉排序树:左子树和右子树本身也是二叉排序树,这使得整个树递归地满足二叉排序树的性质。
数据库
1. JOIN
我们可以通过两个简单的表来演示不同类型的 SQL JOIN。
假设有两个表 Customers 和 Orders:
Customers 表:
| CustomerID | CustomerName |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
Orders 表:
| OrderID | CustomerID | Product |
|---|---|---|
| 101 | 1 | Book |
| 102 | 2 | Pen |
| 103 | 4 | Notebook |
1. INNER JOIN 示例
SELECT Customers.CustomerID, Customers.CustomerName, Orders.Product
FROM Customers
INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID;结果:
| CustomerID | CustomerName | Product |
|---|---|---|
| 1 | Alice | Book |
| 2 | Bob | Pen |
解释: INNER JOIN 只返回两个表中都有匹配行的记录。因为 CustomerID = 3 的 Charlie 没有对应的订单,CustomerID = 4 的订单也没有对应的客户,所以这些行不会出现在结果中。
2. LEFT JOIN 示例
SELECT Customers.CustomerID, Customers.CustomerName, Orders.Product
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;结果:
| CustomerID | CustomerName | Product |
|---|---|---|
| 1 | Alice | Book |
| 2 | Bob | Pen |
| 3 | Charlie | NULL |
解释: LEFT JOIN 返回左表中的所有记录,即使右表中没有匹配的记录。因为 Charlie 没有订单,所以他的 Product 列为 NULL。
3. RIGHT JOIN 示例
SELECT Customers.CustomerID, Customers.CustomerName, Orders.Product
FROM Customers
RIGHT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;结果:
| CustomerID | CustomerName | Product |
|---|---|---|
| 1 | Alice | Book |
| 2 | Bob | Pen |
| 4 | NULL | Notebook |
解释: RIGHT JOIN 返回右表中的所有记录,即使左表中没有匹配的记录。因为 OrderID = 4 的订单没有对应的客户,所以 CustomerName 列为 NULL。
4. FULL JOIN 示例
SELECT Customers.CustomerID, Customers.CustomerName, Orders.Product
FROM Customers
FULL JOIN Orders ON Customers.CustomerID = Orders.CustomerID;结果:
| CustomerID | CustomerName | Product |
|---|---|---|
| 1 | Alice | Book |
| 2 | Bob | Pen |
| 3 | Charlie | NULL |
| 4 | NULL | Notebook |
解释: FULL JOIN 返回两个表中的所有记录。对于没有匹配的记录,会显示 NULL。所以,Charlie 没有订单,Order 101 没有对应的客户,结果中都显示 NULL。
2. 索引的作用
示例场景:
假设我们有一个名为 employees 的表,用于存储公司员工的信息,表结构如下:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
department VARCHAR(50),
salary DECIMAL(10, 2)
);其中,employee_id 是主键,代表每个员工的唯一标识。
没有索引的查询:
假设这个表里有一百万条记录,现在你想查询所有姓为 “Smith” 的员工:
SELECT * FROM employees WHERE last_name = 'Smith';没有索引的情况下,数据库必须对整个 employees 表进行全表扫描(Full Table Scan),也就是从第一条记录一直到最后一条记录,逐条检查 last_name 是否等于 “Smith”。
- 全表扫描的代价:对于一百万条记录,可能需要遍历所有的记录,时间复杂度为 O(n),查询速度会非常慢,特别是在大表中。
建立索引:
为了加速这个查询,我们可以在 last_name 列上创建一个索引:
CREATE INDEX idx_last_name ON employees(last_name);索引创建之后,数据库会在后台构建一个数据结构(例如 B-树),以 last_name 作为键来排序和存储记录的位置指针。
有索引的查询:
再执行相同的查询:
SELECT * FROM employees WHERE last_name = 'Smith';有索引的情况下,查询过程如下:
- 查询索引:数据库首先查询
idx_last_name索引,利用索引的排序特性,快速定位到所有last_name为 “Smith” 的记录。对于 B-树结构,查找的时间复杂度为 O(log n)。 - 获取记录:找到符合条件的索引后,数据库通过索引中的指针直接访问对应的记录,而不需要扫描整个表。
- 结果:通过索引,数据库可以极大地减少需要扫描的记录数,查询速度大幅提升,特别是在大表中。
索引的实际作用:
为了更好理解,我们假设 employees 表的 last_name 列包含以下示例数据:
| employee_id | first_name | last_name | department | salary |
|-------------|------------|-----------|------------|---------|
| 1 | John | Smith | HR | 50000.00|
| 2 | Alice | Johnson | IT | 60000.00|
| 3 | Bob | Smith | Finance | 55000.00|
| ... | ... | ... | ... | ... |- 没有索引时:数据库从头开始扫描每一条记录,即使找到了匹配的记录(如 John Smith),它仍然必须继续扫描所有记录以确保找到所有匹配项。
- 有索引时:数据库直接跳转到
Smith这个位置开始检索,并且因为索引是排序的,能够快速定位所有Smith的记录。
其他类型的索引:
1. 主键索引:
- 自动创建:当你为表创建一个主键时,数据库会自动为这个主键创建一个唯一索引。例如,
employee_id列上默认有主键索引,所有基于employee_id的查询都会非常快。
2. 联合索引(复合索引):
示例:如果经常查询包含department和last_name的条件,可以创建一个联合索引:
CREATE INDEX idx_dept_last_name ON employees(department, last_name);效果:这个索引会优化查询,例如:
SELECT * FROM employees WHERE department = 'IT' AND last_name = 'Smith';原理:数据库会先根据
department查找,再根据last_name进一步过滤,查询效率更高。
索引的代价:
虽然索引提高了查询效率,但也有一定的代价:
- 存储开销:索引占用额外的存储空间。如果表中的数据量非常大,索引也会占用大量磁盘空间。
- 维护开销:在插入、更新或删除记录时,数据库不仅需要修改表中的数据,还需要更新相关的索引。这会增加写操作的时间成本。
总结:
- 索引的优势:主要在于提高查询速度,特别是在大数据集上,可以显著减少查询时间。
- 索引的选择:应基于查询的频率和类型来决定在哪些列上建立索引。通常,在经常用于查询条件的列(如
WHERE、JOIN等操作的列)上建立索引,可以带来明显的性能提升。
通过这个例子,可以清楚地看到索引在提高数据库查询效率方面的作用,以及它的工作原理。
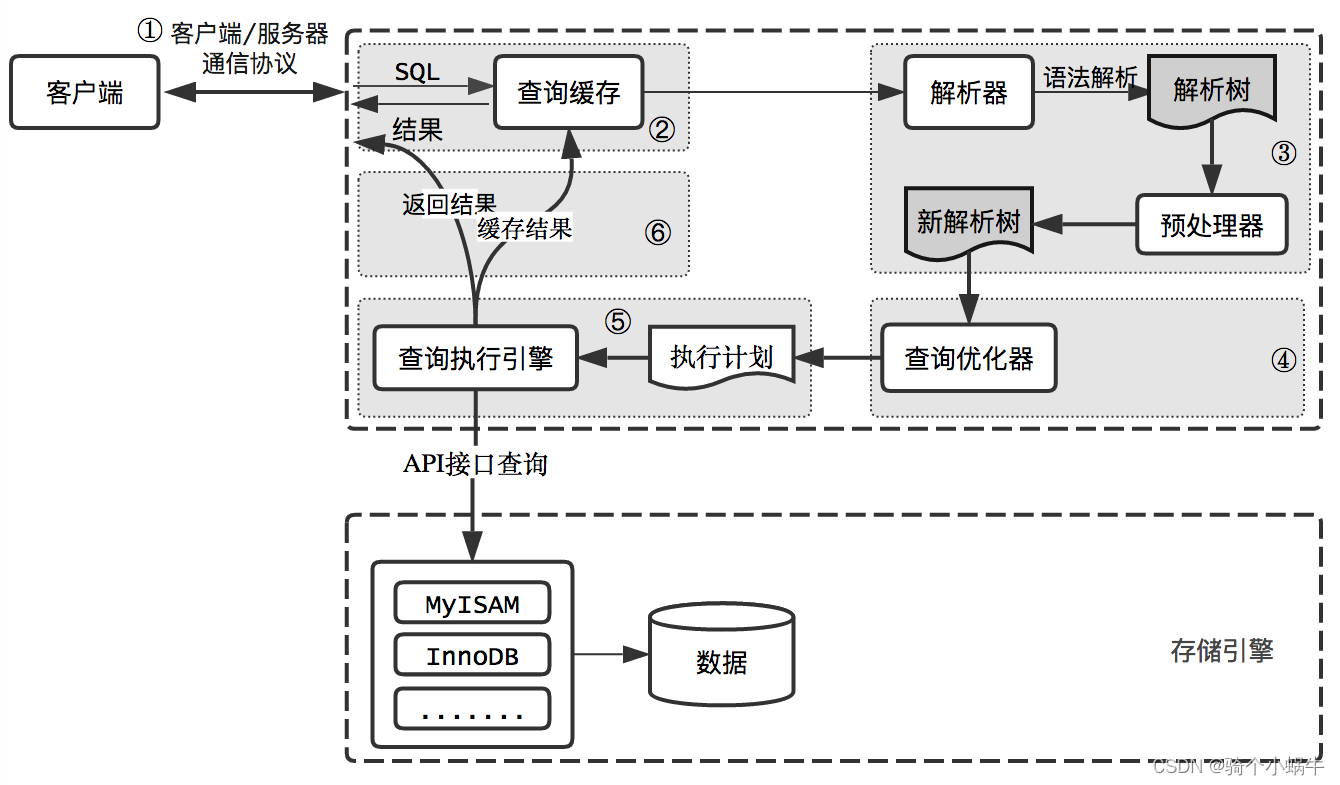
3. 一条查询语句在MySql服务端的执行过程
4. TPS Transactions Per Second
在数据库系统中,TPS 是 Transactions Per Second 的缩写,指的是系统每秒能够处理的事务数。它是衡量数据库系统性能的重要指标,特别是在高并发场景下。
什么是事务(Transaction)?
事务是数据库操作的一个逻辑单元,它通常包括一组数据库操作(如读取、写入、更新、删除),这些操作要么全部成功,要么全部失败。事务通常遵循 ACID 特性:
- Atomicity(原子性): 事务的所有操作要么全部完成,要么全部回滚。
- Consistency(一致性): 事务完成后,数据库必须从一个一致性状态转换到另一个一致性状态。
- Isolation(隔离性): 事务之间互不干扰,一个事务的执行不会影响其他事务。
- Durability(持久性): 事务一旦提交,数据的变更是永久性的,即使系统崩溃也不会丢失。
TPS 的含义:
- TPS 表示每秒可以执行的事务数量,通常用于评估数据库系统在高并发环境下的性能。
- TPS 值越高,意味着系统在相同时间内能够处理的事务数量越多,表明系统的处理能力更强。
- TPS 是数据库性能测试中的关键指标,通常与系统的响应时间、延迟、吞吐量等指标一起使用,全面反映数据库的运行效率。
5. 数据库的聚簇索引和非聚簇索引的区别
| 特性 | 聚簇索引(Clustered Index) | 非聚簇索引(Non-clustered Index) |
|---|---|---|
| 数据物理存储顺序 | 数据按照索引键值排序存储 | 数据存储顺序与索引无关 |
| 索引结构 | 索引的叶子节点是数据行 | 索引的叶子节点是指向数据的指针 |
| 数据检索效率 | 检索速度更快(不需要回表) | 检索较慢,需要回表 |
| 适用场景 | 范围查询或排序 | 精确查找或多字段查询 |
| 插入和更新性能 | 较低(数据可能需要重排) | 较高 |
| 一个表的数量限制 | 一个表只能有一个聚簇索引 | 一个表可以有多个非聚簇索引 |
数据库在查询某一行数据时,不会逐个字段进行匹配,而是通过索引加速查找。如果没有索引,则会使用全表扫描来逐行检查,这种情况下才会逐个字段进行匹配操作。
你在一个电子商务平台的数据库里有一张 Orders 表,用于存储订单信息。表结构如下:
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
TotalAmount DECIMAL(10, 2)
);OrderID 是每个订单的唯一标识,OrderDate 是订单的日期,CustomerID 是客户的编号,TotalAmount 是订单的总金额。
聚簇索引的情况
我们可以为 OrderID 字段创建一个 聚簇索引,因为每个订单都有唯一的 OrderID,并且可以根据这个字段经常进行查找。由于 OrderID 是主键,数据库系统一般会自动为主键创建一个聚簇索引:
ALTER TABLE Orders ADD PRIMARY KEY (OrderID);物理存储:创建了聚簇索引后,
Orders表中的数据将按照OrderID的顺序在磁盘上物理存储。如果你查看硬盘上的数据文件,你会看到订单数据是按照OrderID排序存储的。查询效率:当你使用
OrderID进行查询时,比如:SELECT * FROM Orders WHERE OrderID = 1234;因为
OrderID是聚簇索引,数据库可以直接通过索引找到相应的数据行,不需要额外步骤。数据行就是索引的叶子节点,查询速度非常快。缺点:如果你频繁按
OrderID顺序插入新订单,数据库需要不断地重新排列存储数据,可能会影响插入性能。
非聚簇索引的情况
现在你发现你经常需要按 OrderDate 查询订单,比如按日期范围查询过去某一天的订单。因此你为 OrderDate 创建了一个 非聚簇索引:
CREATE INDEX idx_order_date ON Orders (OrderDate);物理存储:在创建非聚簇索引后,数据库并不会改变数据的物理存储顺序(它依然按
OrderID存储)。但是,数据库会为OrderDate创建一个额外的索引结构。这个索引结构中包含OrderDate和OrderID(指向数据行的地址),并且是按OrderDate排序的。查询效率:当你使用
OrderDate进行查询时,比如:SELECT * FROM Orders WHERE OrderDate = '2024-10-03';数据库会先在
OrderDate的非聚簇索引中查找符合条件的OrderDate值,然后通过OrderID指针找到实际的数据行。这种查找过程会涉及两步:先通过索引找到指针,再通过指针找到数据行,这就是“回表”的过程。缺点:相比聚簇索引,非聚簇索引的查询性能稍差,因为它需要回表操作。
6.
7.
Linux系统使用
1. 文件权限
在 Linux 和类 Unix 操作系统中,每个文件和目录都有一组权限,用来控制谁可以读取、写入或执行该文件或目录。这些权限可以帮助系统管理员确保只有授权的用户能够访问或修改系统中的文件和目录。
文件权限的基本概念
文件权限分为三种类型,分别对应三类用户:
- 用户(User / Owner): 文件的所有者。
- 组(Group): 拥有访问权限的用户组,文件所有者可以指定文件所属的用户组。
- 其他用户(Others): 既不属于文件所有者,也不属于文件所属的组的所有其他用户。
权限类型
对于每种用户类型,有三种基本权限:
- 读取(Read,
r): 允许查看文件内容或列出目录内容。 - 写入(Write,
w): 允许修改文件内容或在目录中创建、删除文件。 - 执行(Execute,
x): 允许执行文件(如果是可执行程序或脚本),或者进入目录。
权限表示法
权限可以通过两种方式表示:符号表示法和八进制表示法。
1. 符号表示法
权限通常用 r, w, x 来表示,例如:
- ```
rwxr-xr–- `rwx`: 用户(Owner)拥有读取、写入和执行权限。 - `r-x`: 组(Group)拥有读取和执行权限。 - `r--`: 其他用户(Others)只有读取权限。 这个表示法分为三组,每组三个字符,分别对应用户、组和其他用户的权限。 ##### 2. 八进制表示法 权限也可以用一个三位的八进制数来表示,其中每位代表一组权限: - `4` 代表 `r` (读取权限) - `2` 代表 `w` (写入权限) - `1` 代表 `x` (执行权限) 例如,`rwxr-xr--` 可以用八进制表示为 `755`: - 用户(Owner):`rwx` = 4 + 2 + 1 = 7 - 组(Group):`r-x` = 4 + 0 + 1 = 5 - 其他用户(Others):`r--` = 4 + 0 + 0 = 4 所以 `rwxr-xr--` 对应的八进制权限是 `755`。 **查找某个目录下没有执行权限的js文件** ```bash find /path/to/directory -name "*.js" ! -perm /u=x
2. 限制某个用户使用cpu的时长
ulimit -t 3600
3. 显示test.c中包含main的行
grep 'main' test.c
4.
代码
C
1. pipe管道
buf[n] = "\0"; 这里要注意,你写入 buf[n]的数据是一个指向 "\0"的指针。而不是你想要的 \0,所以在标准输入台输出的时候,会显示乱码。需要换成 buf[n] = '\0'这样才能算作是字符串的结束标志。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main(){
int pipe_fd[2];
pid_t pid;
char buf[1024];
if (pipe(pipe_fd) == -1){
perror("pipe");
return 1;
}
pid = fork();
if (pid < 0){
perror("fork");
return 1;
}
if(pid == 0){//子进程
close(pipe_fd[1]);//close write of pipe_fd
int n = read(pipe_fd[0], buf, sizeof(buf)-1);
if (n > 0){
buf[n] = "\0"; // 这里要注意
printf("subprocess read data:%s\n",buf);
}
close(pipe_fd[0]);
}else{
close(pipe_fd[0]); // close read of pipe_fd
const char* msg = "Hello from parent process!";
write(pipe_fd[1], msg, strlen(msg));
close(pipe_fd[1]);
wait(NULL);
}
return 0;
}2. socketpair
socketpair 是一种用于在两个进程(例如父进程和子进程)之间创建双向通信通道的技术。它创建了一对相互连接的套接字(socket),使得两个进程可以通过文件描述符来进行数据读写,类似于管道(pipe),但 socketpair 提供了全双工的通信,即两个进程可以同时读写,而不仅仅是单向的。
socketpair 的技术要点:
- 通信协议:
socketpair使用 UNIX 域套接字 (AF_UNIX) 进行本地进程间通信。这种通信机制适用于同一台机器上的进程间通信,而不是基于网络的进程通信。 - 双向通信:
socketpair与pipe不同,管道通常是单向的,而socketpair是双向的。每个文件描述符都可以读写数据,两个进程之间能够相互通信。 - 阻塞与非阻塞:
socketpair可以工作在阻塞或非阻塞模式下。默认情况下,它是阻塞的,也就是说,如果某一端没有准备好读取数据,写入数据的进程可能会被阻塞。
socketpair 的函数签名:
int socketpair(int domain, int type, int protocol, int sv[2]);domain: 通信域,通常使用AF_UNIX,即 UNIX 域套接字,用于本地进程间通信。type: 套接字类型,常见的有SOCK_STREAM(流式套接字)和SOCK_DGRAM(数据报套接字)。流式套接字提供面向连接的字节流通信,类似于 TCP。protocol: 通常设置为 0,表示使用默认协议。sv[2]: 一个数组,用来存放返回的两个文件描述符,sv[0]和sv[1]分别代表父进程和子进程的套接字。
代码分析:
int file_descriptors[2];
assert(socketpair(AF_UNIX, SOCK_STREAM, 0, file_descriptors) == 0);
int parent_socket = file_descriptors[0];
int child_socket = file_descriptors[1];这段代码的作用是创建一对连接的套接字,通过 socketpair(AF_UNIX, SOCK_STREAM, 0, file_descriptors) 来生成两个文件描述符,分别用于父进程和子进程的通信。
file_descriptors[0]是父进程使用的套接字文件描述符。file_descriptors[1]是子进程使用的套接字文件描述符。
接下来,父进程和子进程可以通过 parent_socket 和 child_socket 进行数据的交换。数据写入父进程的文件描述符后,子进程可以通过它的文件描述符读取该数据,反之亦然。
使用场景:
在你提供的代码中,socketpair 用于在父进程和子进程(进入“监狱”的进程)之间通信。子进程无法直接访问系统资源(如文件系统或网络),因此它必须依赖父进程来获取数据或进行操作。在这种情况下,socketpair 是非常适合的技术,因为它提供了一条安全的通信通道。
c复制代码puts("Creating a `socketpair` that the child and parent will use to communicate. This is a pair of file descriptors that are");
puts("connected: data written to one can be read from the other, and vice-versa.\n");这说明了 socketpair 的核心功能:数据可以在父子进程之间双向传递。子进程受限于 “jail” 环境,只有通过这种套接字与父进程通信,可能需要从父进程获取关键信息(如 flag)。
工作原理:
- 创建进程:父进程首先通过
fork()创建子进程。父进程保留一个文件描述符,子进程保留另一个。 - 双向通信:父进程和子进程可以通过套接字互相发送和接收数据。任何写入
parent_socket的数据可以被child_socket读取,反之亦然。 - 监狱环境:子进程被限制在 “jail” 中,它无法直接访问外部资源,依赖父进程通过
socketpair提供服务。挑战中提到的 “convince the parent process to give it to you”(让父进程提供 flag),意味着子进程必须通过精心构建的通信来请求父进程,才能拿到 flag。
socketpair 的优势:
- 本地进程间通信的高效性:
socketpair不需要经过网络堆栈,适合高效的本地进程间通信。 - 双向通信:可以实现数据的双向传输,方便父子进程或任意两个进程之间的交互。
- 隔离和安全:父进程和子进程通过套接字隔离,它们只能通过套接字通信,子进程在受限的 jail 环境下不会直接访问系统资源。
总结:
socketpair 是一种强大且简洁的进程间通信机制,适用于本地的父子进程间的双向通信。在你提供的例子中,父子进程通过 socketpair 进行信息传递,子进程在受限环境下试图从父进程获取 flag,是一个经典的 CTF 场景。
python
2. python多线程
问题描述:同学遇到了一个问题,即在开启多线程处理数据时,并使用 tqdm.tqdm(p.imap_unordered(worker, t_args), total=len(t_args))进行统计时,总是会在最后卡住。
原始代码:
import multiprocessing
import time
import os
import tqdm
import signal
def sing(item):
singer = item[0]
song = item[1]
if singer%5==0 and singer!=0:
os.kill(os.getpid(), signal.SIGKILL)
print('running ,',str(singer),' pid: ',os.getpid())
if __name__ == '__main__':
t_args = [(i,1) for i in range(30)]
print(os.getpid())
print(os.cpu_count())
p = multiprocessing.Pool(processes=None, maxtasksperchild=5)
for _ in tqdm.tqdm(p.imap_unordered(sing, t_args), total=len(t_args)):
pass
# p.imap_unordered(sing, t_args)
p.close()
p.join()这里无论是否使用tqdm统计p.imap_unorder的完成,都会卡住。
原因分析
在sing函数中使用 os.kill(os.getpid(), signal.SIGKILL)结束子进程时,子进程直接结束了。父进程的进程池无法收到子进程结束的状态,所以他会一直等待子进程返回状态,但是子进程已经结束了。进程池需要通过 SIGCHLD 信号了解子进程的终止状态。如果子进程被强制终止(如 SIGKILL 信号–),进程池不会收到 SIGCHLD 信号,因此会一直等待子进程完成。
当进程正常退出时,当一个进程正常退出时(例如,通过 exit() 或 return),它会向其父进程发送 SIGCHLD 信号。父进程(在这种情况下是进程池)会捕获到这个信号,并更新其内部状态以反映子进程已经终止。而 SIGKILL 是一个无法被捕获或忽略的信号。它会立即终止进程而不进行任何清理工作,也不会向父进程发送终止通知。因此,进程池无法知道子进程已经终止,可能会导致资源泄漏或进程池状态不一致。
所以我们需要在子进程中加入异常信号处理函数,在子进程接受到信号量以后,发送相应的信号量到父进程。
正常版本
import multiprocessing
import time
import os
import tqdm
import signal
# 进程使用以及传参
def sing(item):
singer = item[0]
song = item[1]
if singer%5==0 and singer!=0:
print(' pid: ',os.getpid())
os.kill(os.getpid(), signal.SIGTERM)
# print('running ,',str(singer),' pid: ',os.getpid(),'pgid: ', os.getpgid(os.getpid()))
# print('running ,',str(singer),' pid: ',os.getpid())
# print('sing:',os.getppid(), multiprocessing.current_process().name)
print(f'{singer}唱{song}')
def handle_signal(signum, frame):
print(f'Process {os.getpid()} received signal {signum}')
raise SystemExit('Terminated')
def worker(item):
signal.signal(signal.SIGTERM, handle_signal) # 创建信号处理函数,这样通过os向子进程发送信号以后,子进程可以向父进程发送信号。
try:
sing(item)
except Exception as e:
print(f'Unexpected error in process {os.getpid()}: {e}')
if __name__ == '__main__':
t_args = [(i,1) for i in range(30)]
print(os.getpid())
print(os.cpu_count())
p = multiprocessing.Pool(processes=None, maxtasksperchild=5)
for _ in tqdm.tqdm(p.imap_unordered(worker, t_args), total=len(t_args)):
pass
# p.imap_unordered(sing, t_args)
p.close()
p.join()
输出
可以观察到,子进程的 try/catch语句并没有打印相应的报错信息。但是信号处理函数中的打印语句是打印出来的。
186677
12
0%| | 0/30 [00:00<?, ?it/s]0唱1
1唱1
3唱1
2唱1
pid: 186678
Process 186678 received signal 15
Process 186678 exiting: Terminated
4唱1
6唱1
7唱1
8唱1
9唱1
pid: 186687
12唱1
Process 186687 received signal 15
Process 186687 exiting: Terminated
11唱1
13唱1
pid: 186688
Process 186688 received signal 15
Process 186688 exiting: Terminated
14唱1
16唱1
18唱1
17唱1
19唱1
21唱1
pid: 186686
24唱1
Process 186686 received signal 15
Process 186686 exiting: Terminated
23唱1
22唱1
26唱1
27唱1
pid: 186682
Process 186682 received signal 15
28唱1
Process 186682 exiting: Terminated
29唱1
100%|█████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:00<00:00, 3469.43it/s]分析
在代码中,当子进程接收到 SIGTERM 信号时,信号处理函数 handle_signal 会立即执行,通常会中断当前正在进行的操作。这意味着信号处理函数的执行优先级是高于 try/catch 块中的代码的。所以当 handle_signal引发异常以后,子进程中 try/catch语句中的报错是无法打印出来的。
相关知识
1. 进程id pid、父进程id ppid,进程组id pgid之间的关系
- 进程ID (PID):
- 每个进程在创建时会被分配一个唯一的进程ID。
- 父进程ID (PPID):
- 每个进程都有一个父进程,父进程的进程ID称为父进程ID (PPID)。
- 进程组ID (PGID):
- 默认情况下,进程组ID等于创建它的父进程的进程ID。即使一个进程创建了新的进程,这些新进程将继承父进程的进程组ID。
- 进程组允许将多个相关的进程组织在一起,通常由第一个创建进程的PID作为PGID。
import os
import multiprocessing
def worker():
pid = os.getpid()
ppid = os.getppid()
pgid = os.getpgid(pid)
print(f"Process ID (PID): {pid}")
print(f"Parent Process ID (PPID): {ppid}")
print(f"Process Group ID (PGID): {pgid}")
if __name__ == '__main__':
# 创建一个新的进程
p = multiprocessing.Process(target=worker)
p.start()
p.join()
# 主进程的信息
print(f"Main Process ID (PID): {os.getpid()}")
print(f"Main Process Group ID (PGID): {os.getpgid(os.getpid())}")
输出为
Main Process ID (PID): 178045
Main Process Group ID (PGID): 178045
Process ID (PID): 178046
Parent Process ID (PPID): 178045
Process Group ID (PGID): 178045在这个例子中:
- 主进程的PID是 178045,并且它的PGID也是 178045。
- 当主进程创建了一个新的子进程时,子进程的PID变成了 178046。
- 子进程的PPID是创建它的主进程的PID,即 178045。
- 默认情况下,子进程继承了父进程的PGID,所以子进程的PGID仍然是 178045。
2. os.kill发送信号
使用 os.kill 函数向某个进程发送信号,实际上是由操作系统的内核负责产生信号并将其发送到指定进程。调用 os.kill 向进程发送信号时,如果进程注册了信号处理函数,该函数会优先执行。如果处理函数未终止进程,默认的信号处理行为将不会执行,进程会继续运行。这确保了用户可以通过信号处理函数实现自定义行为,而不是立即终止进程或触发其他默认行为。
信号的产生和发送过程
- 调用
os.kill函数:- 当你在代码中调用
os.kill(pid, signal.SIGTERM)时,Python 会将这个请求传递给操作系统的内核。这里,pid是目标进程的进程ID,signal.SIGTERM是要发送的信号。
- 当你在代码中调用
- 内核处理信号请求:
- 操作系统的内核接收到
os.kill的请求后,会验证请求的合法性,包括检查发送信号的进程是否有权限向目标进程发送该信号。 - 如果请求合法,内核会产生对应的信号。
- 操作系统的内核接收到
- 信号的传递:
- 内核将生成的信号传递给目标进程。信号是一种异步通知机制,可以中断进程的正常执行,并引发预定义的信号处理程序。
- 信号的处理:
- 目标进程接收到信号后,如果注册了相应的信号处理程序(如使用
signal.signal(signal.SIGTERM, handle_signal)注册的处理函数),处理程序会被调用。 - 如果没有注册处理程序,默认的信号处理行为将被执行。对于
SIGTERM,默认行为是终止进程。
- 目标进程接收到信号后,如果注册了相应的信号处理程序(如使用
3. 信号处理函数、try/except 语句和系统默认行为的优先级关系
信号处理函数:
- 当进程接收到信号时,如果该信号有用户定义的处理函数,操作系统会立即调用这个处理函数。
- 信号处理函数的调用是异步的,可以中断进程正在执行的任何代码,包括
try块中的代码。 - 信号处理函数具有最高优先级,因为它可以在任何时候中断进程的执行。
try/except 语句:
try/except块用于捕获和处理异常。在信号处理函数中引发的异常可以被try/except块捕获。- 当信号处理函数引发异常时,这个异常会中断当前代码的执行,并跳转到最近的
try/except块。 try/except块的优先级低于信号处理函数,但高于默认信号处理行为。
系统默认行为:
- 如果进程没有定义信号处理函数,或者信号处理函数没有引发异常,操作系统会执行该信号的默认处理行为。
- 默认处理行为的优先级最低,只有在没有用户定义的信号处理函数或信号处理函数没有覆盖默认行为时才会执行。
4. 为什么try/except语句引发的异常,进程池无法接受到?
让我们深入探讨为什么进程池可以正确处理通过信号处理函数引发的 SystemExit 异常,但通过 try/except 语句引发的 SystemExit 异常却不能正确处理。
3. 信号处理函数和 try/except 语句的差异
- 信号处理函数的行为:
- 当一个进程接收到信号(如
SIGTERM)时,操作系统会立即调用相应的信号处理函数。这中断了当前进程的执行,并处理信号。 - 在信号处理函数中引发
SystemExit异常,会立即导致进程退出,并且操作系统会通知父进程(即进程池)该子进程已终止。 - 这种行为是操作系统级别的处理,确保了父进程能够捕获到子进程的终止状态。
- 当一个进程接收到信号(如
try/except语句的行为:try/except语句是在用户代码层面进行异常处理。当在except块中引发SystemExit异常时,Python 解释器会认为这是一个正常退出过程。- 但在某些情况下,尤其是在多进程环境下,这种由用户代码引发的
SystemExit可能不会被进程池正确感知到。这可能与 Python 多进程模块内部的异常传播机制有关。
4. pwntool,在不使用p.recvall()的情况下,p.poll()轮询将无法获得进程的退出码
在你的代码中,p.poll() 用于轮询进程的退出状态,p.recvall() 则是用来从进程的标准输出中读取数据。当你调用 p.poll() 时,它检查进程是否已经终止,并返回进程的退出码。如果进程还在运行,它返回 None。
现象:
如果你不调用 p.recvall() 或其他类似的读取操作,进程可能不会像预期一样结束。这背后的原因与 缓冲区 和 管道 的工作原理有关。
原因:
当你启动 process 时,标准输出(stdout)和标准输入(stdin)通常会通过管道进行通信。这些管道有一个固定的缓冲区。如果缓冲区满了而没有被读取,那么进程可能会阻塞,等待缓冲区被清空。这意味着如果你没有调用 p.recvall() 或其他读取方法来读取输出数据,进程可能会因为缓冲区满了而一直处于等待状态,从而无法结束。
具体的工作流程是这样的:
- 你在进程中执行了
sendline(shellcode),将 shellcode 发送给目标进程。 - 目标进程可能会产生一些输出,比如标准输出或错误输出,写入到它的管道中。
- 如果你没有读取这些输出,管道的缓冲区会逐渐填满。
- 一旦管道缓冲区满了,目标进程在试图向输出流中写入更多数据时会被阻塞,导致进程不能正常结束。
- 在这种情况下,
p.poll()将无法返回一个有效的退出码,因为目标进程仍在等待缓冲区被读取。
解决方法:
为了避免这种情况,你需要确保从进程的标准输出或错误输出中读取数据,以防止缓冲区阻塞进程的正常退出。调用 p.recvall() 可以读取进程的所有输出,并且在进程终止后,读取过程会自动结束。
java
1. 为什么java不能实现真正意义上的泛型?类似于C++的模板。
为了说明为什么 Java 如果采用类似 C++ 的模板机制就不能实现向后兼容性,我们可以通过以下例子来进行解释。
向后兼容性
Java 的设计理念之一是向后兼容性,即新版本的 Java 能够运行老版本编写的程序。这意味着即便 Java 引入了泛型特性,已经存在的老代码(未使用泛型)也应该能够继续运行。
C++ 模板和 Java 泛型的区别
- C++ 模板:在编译期生成针对每种类型的独立代码。编译器会为每个模板实例生成不同的函数或类。
- Java 泛型:通过类型擦除来实现泛型,确保在运行时只有一套字节码。
例子:C++ 模板如何导致向后不兼容
假设我们在 C++ 中有如下模板代码:
C++ 模板例子
#include <iostream>
template <typename T>
class Box {
public:
T value;
Box(T val) : value(val) {}
void display() {
std::cout << "Box contains: " << value << std::endl;
}
};
void displayOld(Box<int>& box) {
std::cout << "Old version: Box contains: " << box.value << std::endl;
}
int main() {
Box<int> intBox(123);
intBox.display(); // Box contains: 123
displayOld(intBox); // Old version works fine
Box<std::string> strBox("Hello");
strBox.display(); // Box contains: Hello
}在这个例子中,Box<int> 和 Box<std::string> 是两个完全不同的类,编译器为 int 和 std::string 生成了两个不同的类实例。如果我们将现有的程序扩展为使用 Box<std::string>,之前编译的函数 displayOld(仅处理 Box<int>)将无法处理 Box<std::string>,因为它们是不同的类型。这在向后兼容性上就会出现问题:新增的模板类型与老版本生成的代码无法协作。
Java 泛型向后兼容的方式
为了避免这种问题,Java 采用了类型擦除机制,使得泛型类在编译时只生成一套字节码,这样老代码(没有泛型)依然可以与泛型代码协同工作。
Java 泛型例子
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
ArrayList<String> strList = new ArrayList<>();
strList.add("Hello");
displayOld(strList); // 老代码仍然可以工作
ArrayList<Integer> intList = new ArrayList<>();
intList.add(123);
displayOld(intList); // 仍然兼容老代码
}
// 老版本的函数,不使用泛型
public static void displayOld(ArrayList list) {
System.out.println("Old version: " + list);
}
}类型擦除后,ArrayList<String> 和 ArrayList<Integer> 在运行时实际上是同一个类,即 ArrayList<Object>。因此,旧版的 displayOld 方法仍然可以处理新版本中传入的泛型参数,无论是 ArrayList<String> 还是 ArrayList<Integer>,因为它们都被视为 ArrayList<Object>。
为什么 C++ 模板无法做到向后兼容
- 独立的类实例:C++ 模板在编译时为每个不同类型生成独立的代码。如果老代码只知道如何处理
Box<int>,它就无法处理Box<std::string>,因为在编译时,这些是完全不同的类。 - 模板代码膨胀:由于 C++ 为每个类型实例生成不同的代码,二进制文件大小会膨胀。而如果在新版本中引入了更多类型的实例,旧版本的代码和新版本的模板实例可能无法共存。
- 无法统一处理所有类型:由于 C++ 模板为每种类型生成独立代码,旧的二进制代码无法处理新的类型实例。这就导致如果添加了新类型支持,必须重新编译所有代码。
总结
如果 Java 采用了 C++ 模板机制,那么:
- 老代码和新代码将无法互操作,因为编译期会为每个泛型实例生成独立的代码,老版本的代码不会知道如何处理新版本的泛型类。
- 为了让旧代码处理新的泛型类型,必须重新编译旧代码,这会导致向后兼容性问题。
通过类型擦除,Java 确保了泛型的类型信息在编译时检查,运行时类型被擦除,使得编译后的字节码对所有泛型类型都一样,从而保证了新旧代码的兼容性。
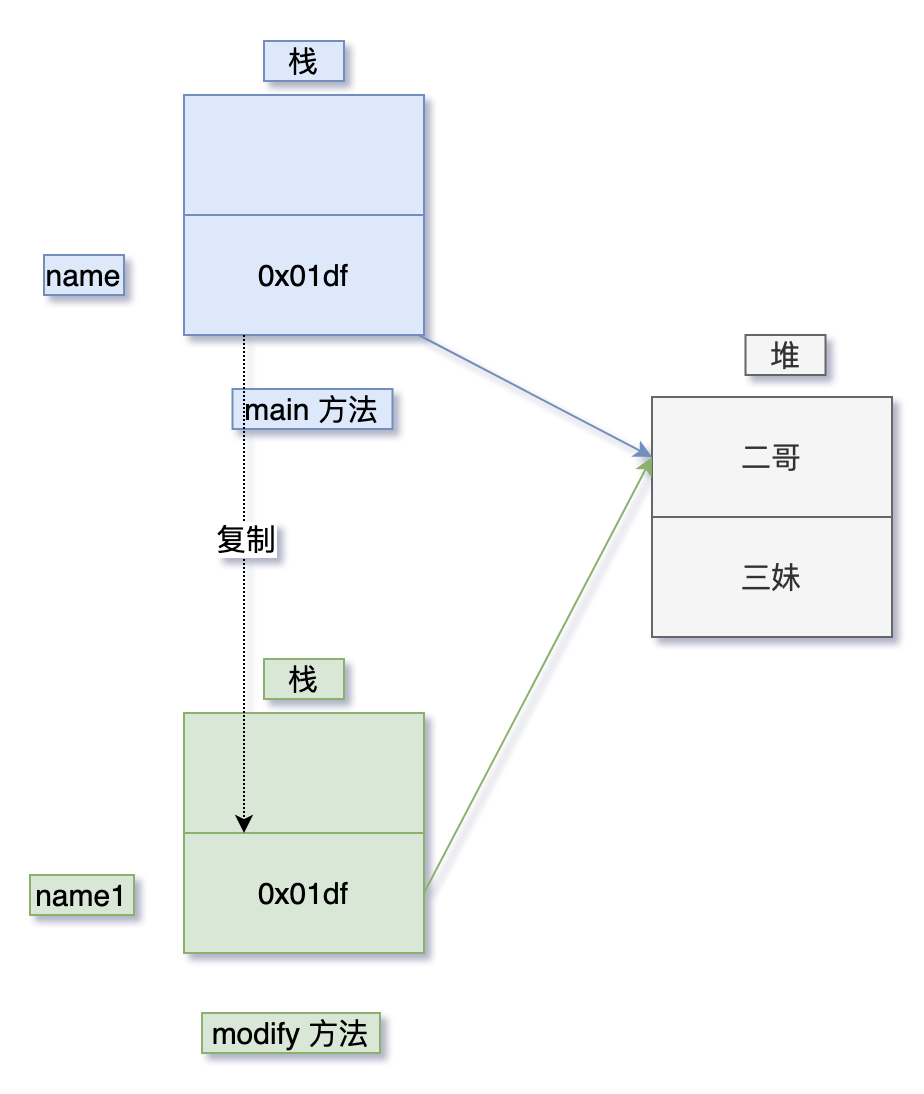
2. java 到底是值传递还是引用传递
- 值传递:当一个参数按照值的方式在两个方法之间传递时,调用者和被调用者其实是用的两个不同的变量——被调用者中的变量(原始值)是调用者中变量的一份拷贝,对它们当中的任何一个变量修改都不会影响到另外一个变量,
- Java 中的参数传递是按值传递的。
- 如果参数是基本类型,传递的是基本类型的字面量值的拷贝。
- 如果参数是引用类型,传递的是引用的对象在堆中地址的拷贝。
- 引用传递: 当一个参数按照引用传递的方式在两个方法之间传递时,调用者和被调用者其实用的是同一个变量,当该变量被修改时,双方都是可见的。
https://javabetter.cn/basic-extra-meal/pass-by-value.html
class ReferenceTypeDemo {
public static void main(String[] args) {
String name = "二哥";
modify(name);
System.out.println(name);
}
private static void modify(String name1) {
name1 = "三妹";
}
}
3. java 深拷贝和浅拷贝
“深拷贝和浅拷贝不同的,深拷贝中的引用类型字段也会克隆一份,当改变任何一个对象,另外一个对象不会随之改变。”浅拷贝不会拷贝引用类型字段,引用类型的变量还是指向的同一个对象。
4. hashCode 与 equals(为什么重写equals方法后,hashCode方法也必须重写)
在Java中,hashCode()和equals()方法有着密切的关系,特别是在使用哈希集合类(如HashSet、HashMap等)时。如果只重写了equals()方法,而不重写hashCode(),可能会导致程序行为不符合预期。
Object类的hashCode()方法的默认实现是基于对象的内存地址来计算哈希值。这意味着每个对象的内存地址不同,因此它们的哈希值通常是不同的。
equals()和hashCode()的作用:
equals():用来比较两个对象是否”相等”。默认情况下,equals()方法比较的是对象的引用(地址),但通常我们会根据对象的属性来判断两个对象是否相等,所以需要重写equals()方法。hashCode():返回一个对象的哈希码,它是对象的一个整数表示,主要用于哈希表中的快速查找。在默认实现中,hashCode()方法基于对象的内存地址生成。
为什么重写equals()方法后,必须重写hashCode()方法?
Java的基本约定:
Java规定了equals()与hashCode()之间的约定,以保证哈希集合类的正常运行:
- 如果两个对象通过
equals()方法比较相等(即obj1.equals(obj2)返回true),那么它们的hashCode()也必须相等。这确保了在哈希表结构中,obj1和obj2会被放到相同的桶中。 - 如果两个对象通过
equals()方法不相等,那么它们的hashCode()可以相同(虽然这不影响正确性,但会降低性能),这称为哈希冲突。
如果不遵守这个约定,会发生什么?
如果只重写了equals()而没有重写hashCode(),就可能违反上述约定,导致以下问题:
- 哈希集合无法正确存储对象: 比如在
HashSet中,如果两个对象被认为是相等的(通过equals()),但它们的hashCode()不同,那么在添加这些对象到HashSet时,它们会被放入不同的桶中,HashSet会错误地认为它们是不同的对象,导致集合中有重复对象。 - 哈希表无法正确查找对象: 在
HashMap中,如果存储了一个对象obj1,而要查找另一个”相等”的对象obj2(即obj1.equals(obj2)为true),如果obj1和obj2的hashCode()不同,HashMap会去不同的桶中查找,可能找不到对象,即使equals()表明它们相等。
在Java中,hashCode()和equals()方法有着密切的关系,特别是在使用哈希集合类(如HashSet、HashMap等)时。如果只重写了equals()方法,而不重写hashCode(),可能会导致程序行为不符合预期。
equals()和hashCode()的作用:
equals():用来比较两个对象是否”相等”。默认情况下,equals()方法比较的是对象的引用(地址),但通常我们会根据对象的属性来判断两个对象是否相等,所以需要重写equals()方法。hashCode():返回一个对象的哈希码,它是对象的一个整数表示,主要用于哈希表中的快速查找。在默认实现中,hashCode()方法基于对象的内存地址生成。
为什么重写equals()方法后,必须重写hashCode()方法?
Java的基本约定:
Java规定了equals()与hashCode()之间的约定,以保证哈希集合类的正常运行:
- 如果两个对象通过
equals()方法比较相等(即obj1.equals(obj2)返回true),那么它们的hashCode()也必须相等。这确保了在哈希表结构中,obj1和obj2会被放到相同的桶中。 - 如果两个对象通过
equals()方法不相等,那么它们的hashCode()可以相同(虽然这不影响正确性,但会降低性能),这称为哈希冲突。
如果不遵守这个约定,会发生什么?
如果只重写了equals()而没有重写hashCode(),就可能违反上述约定,导致以下问题:
- 哈希集合无法正确存储对象: 比如在
HashSet中,如果两个对象被认为是相等的(通过equals()),但它们的hashCode()不同,那么在添加这些对象到HashSet时,它们会被放入不同的桶中,HashSet会错误地认为它们是不同的对象,导致集合中有重复对象。 - 哈希表无法正确查找对象: 在
HashMap中,如果存储了一个对象obj1,而要查找另一个”相等”的对象obj2(即obj1.equals(obj2)为true),如果obj1和obj2的hashCode()不同,HashMap会去不同的桶中查找,可能找不到对象,即使equals()表明它们相等。
示例:
假设我们有一个简单的类Person,只根据名字和年龄来判断相等性:
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && name.equals(person.name);
}
// 假设没有重写 hashCode()
}在上面的代码中,equals()已经重写,两个Person对象如果名字和年龄相同会被认为是相等的。但如果没有重写hashCode(),比如:
Person p1 = new Person("Alice", 25);
Person p2 = new Person("Alice", 25);
Set<Person> set = new HashSet<>();
set.add(p1);
set.add(p2); // 期望p1和p2相等,但实际上它们被认为是不同的对象由于没有重写hashCode(),即使p1.equals(p2)为true,它们的hashCode()可能不同,导致HashSet认为它们是不同的对象,set会错误地存储两个相等的对象。
正确的做法:
为了避免这个问题,重写equals()时,必须同时重写hashCode()。例如:
@Override
public int hashCode() {
return Objects.hash(name, age);
}这样,两个对象如果通过equals()相等,它们的hashCode()也会相等。
总结:
equals()决定两个对象是否相等。hashCode()决定两个对象是否可以放入同一个哈希桶。- 如果只重写
equals()而不重写hashCode(),会破坏哈希集合的行为,导致错误的存储和查找结
5. list的add和remove操作
在 Java 中,List 接口常用于处理有序的集合,提供了一些常用的操作方法,比如 add 和 remove。它的常见实现类有 ArrayList 和 LinkedList,它们的 add 和 remove 方法的性能可能会有所不同。
add 操作
List 的 add 方法有两个重载版本:
**
boolean add(E e)**:在列表的末尾追加一个元素。时间复杂度:
- 对于
ArrayList,如果没有扩容,时间复杂度为 **O(1)**;如果扩容,则为 **O(n)**,因为需要重新分配内存并复制现有元素。 - 对于
LinkedList,时间复杂度为 **O(1)**,因为它只是在链表末尾添加一个节点。
- 对于
示例:
List<String> list = new ArrayList<>(); list.add("apple"); list.add("banana");
**
void add(int index, E element)**:在指定位置插入一个元素。时间复杂度:
- 对于
ArrayList,时间复杂度为 **O(n)**,因为需要移动插入点后面的所有元素。 - 对于
LinkedList,时间复杂度为 **O(n)**,因为需要遍历到指定索引处,找到插入位置。
- 对于
示例:
List<String> list = new ArrayList<>(); list.add(0, "apple"); // 插入到索引 0 位置 list.add(1, "banana"); // 插入到索引 1 位置
remove 操作
List 的 remove 方法也有两个重载版本:
**
E remove(int index)**:根据索引删除指定位置的元素。时间复杂度:
- 对于
ArrayList,时间复杂度为 **O(n)**,因为需要移动被删除元素后面的所有元素。 - 对于
LinkedList,时间复杂度为 **O(n)**,因为需要遍历链表找到指定索引,并执行删除。
- 对于
示例:
List<String> list = new ArrayList<>(); list.add("apple"); list.add("banana"); list.remove(1); // 删除索引 1 位置的 "banana"
**
boolean remove(Object o)**:根据对象内容删除第一个匹配的元素。时间复杂度:
- 对于
ArrayList,时间复杂度为 **O(n)**,因为需要遍历整个列表找到要删除的对象。 - 对于
LinkedList,时间复杂度为 **O(n)**,因为也需要遍历链表找到要删除的对象。
- 对于
示例:
List<String> list = new ArrayList<>(); list.add("apple"); list.add("banana"); list.remove("apple"); // 删除第一个匹配的 "apple"
总结
- add 和 remove 操作在 ArrayList 和 LinkedList 中的性能有差异,具体取决于它们的内部实现方式。
- **
ArrayList**:在末尾添加元素通常是 **O(1)**,但在中间插入或删除则需要移动元素,时间复杂度为 **O(n)**。 - **
LinkedList**:在任意位置添加或删除元素不需要移动其他元素,但由于链表需要遍历,性能为 **O(n)**。
- **
根据具体的需求,选择合适的 List 实现类会对程序性能产生影
6. java的垃圾回收机制
Java 的垃圾回收机制(Garbage Collection,简称 GC)是自动管理内存的功能,开发者不需要显式地释放对象的内存,垃圾回收器会自动检测和释放不再使用的对象,从而防止内存泄漏并优化内存使用。
7. Java 垃圾回收机制的基本原理
Java 使用 堆内存(Heap) 来存储对象。当程序创建新对象时,系统会在堆中分配内存,随着时间的推移,有些对象可能不会再被引用,这些对象就变成了 垃圾。垃圾回收机制的目标是:
- 自动检测哪些对象已经不再被引用;
- 释放这些对象占用的内存;
- 使程序内存使用更加高效。
垃圾回收算法
Java 垃圾回收机制的核心是使用不同的算法来自动管理堆内存。常见的垃圾回收算法包括:
1. 标记-清除算法(Mark-Sweep)
- 步骤:
- 标记(Marking):垃圾回收器会扫描所有活动对象,并将它们标记为存活。
- 清除(Sweep):未被标记的对象会被认为是垃圾,系统将清除它们,释放对应的内存。
- 问题:虽然能够回收垃圾对象,但可能会导致内存碎片化,因为清除后内存空间并不会被紧凑排列。
2. 标记-整理算法(Mark-Compact)
- 步骤:
- 先执行和标记-清除算法一样的标记过程。
- 然后通过整理步骤,将存活的对象移动到内存的一端,形成连续的内存块,消除碎片化问题。
- 优势:避免了内存碎片问题,内存分配效率更高。
3. 复制算法(Copying)
- 将内存区域划分为两部分(通常是新生代使用):活动对象总是位于一部分,当这部分内存用完时,垃圾回收器会将存活的对象复制到另一块内存区域,之后清除原来的区域。
- 优势:这种方式可以快速回收内存,不需要额外的清除或整理步骤。
- 缺点:需要更多的内存,因为它依赖于内存区域划分为两部分。
内存划分及垃圾回收器
Java 的堆内存分为 新生代(Young Generation) 和 老年代(Old Generation)。不同的垃圾回收器使用了这些划分来管理不同生命周期的对象。
- 新生代:用于存放刚刚创建的对象,分为三个区域:Eden 区、Survivor 区(S0、S1)。大部分对象会在新生代中创建并快速回收。新生代的回收称为 Minor GC。
- 老年代:存放生命周期较长的对象,这些对象在多次 Minor GC 后仍存活下来,会被移动到老年代。老年代的回收称为 Major GC 或 Full GC。
常见垃圾回收器
- Serial GC:单线程垃圾回收器,适用于单线程应用。
- Parallel GC:多线程垃圾回收器,使用多个线程并行处理垃圾回收,适用于多核 CPU 的服务器。
- CMS(Concurrent Mark-Sweep)GC:并发垃圾回收器,减少了应用暂停时间,适用于需要低延迟的应用。
- G1(Garbage First)GC:专为大内存、低延迟的应用设计,分区收集内存,提供更好的性能。
垃圾回收触发时机
垃圾回收器在以下情况会被触发:
- 新生代满了,触发 Minor GC;
- 老年代满了,触发 Major GC 或 Full GC;
- 手动调用
System.gc(),会建议垃圾回收器运行(但不是强制)。
垃圾回收优化
通过调整堆大小、垃圾回收算法和线程,可以优化 Java 应用的性能:
- 调整堆内存大小:
-Xms设置初始堆大小,-Xmx设置最大堆大小。 - 调整新生代和老年代比例:通过参数如
-XX:NewRatio调整比例。 - 选择合适的垃圾回收器:例如
-XX:+UseG1GC使用 G1 GC。
小结
Java 的垃圾回收机制通过多种算法和回收器,实现了自动内存管理,极大地简化了开发者的内存操作负担。合理配置垃圾回收器可以提升程序的性能,尤其是针对大规模、高并发的应用。
8. java是多继承吗
Java 不是多继承的语言。它不允许一个类继承多个类,即 类的多继承 在 Java 中是不支持的。Java 只允许一个类通过 extends 关键字继承自一个父类,这样可以避免多继承中的 菱形继承问题(即多个父类有相同的方法,子类不确定调用哪个版本)。
为什么 Java 不支持多继承?
多继承容易引发复杂性,尤其是在以下两种情况下:
菱形继承问题:当两个父类有同名的字段或方法时,子类继承时会遇到冲突,可能不知道应该使用哪个父类的实现。
示例:
class A { void display() { System.out.println("Class A"); } } class B { void display() { System.out.println("Class B"); } } // 如果类 C 继承 A 和 B,会不知道调用哪个 display 方法。增加复杂性:维护代码会变得困难,因为子类需要同时处理多个父类的行为和状态。
Java 提供的替代方案:接口
虽然 Java 不支持类的多继承,但它允许一个类实现多个接口,这可以作为多继承的替代方案。
- 接口:接口定义了一组抽象方法,任何类都可以通过
implements关键字实现多个接口,从而获取多种行为特性。接口没有方法的具体实现,不会带来多继承中方法冲突的问题。
示例:
interface A {
void display();
}
interface B {
void show();
}
class C implements A, B {
@Override
public void display() {
System.out.println("Implementing display from A");
}
@Override
public void show() {
System.out.println("Implementing show from B");
}
}
public class Test {
public static void main(String[] args) {
C obj = new C();
obj.display(); // 输出: Implementing display from A
obj.show(); // 输出: Implementing show from B
}
}Java 8 的默认方法
Java 8 引入了接口的 默认方法(default methods),即接口中的方法可以有默认的实现。这意味着接口的实现类不需要重新实现这些默认方法,但如果实现类需要,可以覆盖它们。
如果一个类实现了多个接口,并且这些接口有相同的默认方法实现,那么子类必须明确指定使用哪个接口的方法实现,避免冲突。
总结:
- Java 不支持类的多继承,但支持接口的多继承。
- 通过接口和接口的默认方法,Java 提供了功能上类似多继承的能力,同时避免了多继承的复杂性。
9. spring boot 项目如何启动
在 Spring Boot 项目中,各个模块之间的启动和交互依赖于 Spring 框架 的核心特性,如 依赖注入、自动配置 和 组件扫描。下面是这些模块如何相互启动和协作的一个概述:
1. 启动类(BaselinecheckApplication.java)的启动流程
Spring Boot 项目的启动类通常带有
@SpringBootApplication注解。@SpringBootApplication是一个复合注解,包含了以下重要功能:
@EnableAutoConfiguration:启用 Spring Boot 的自动配置机制,会根据项目中的依赖自动配置相关的 bean。@ComponentScan:启用组件扫描,扫描当前包及其子包下的所有 Spring 组件(如@Controller,@Service,@Repository,@Component等)。@Configuration:标记该类为一个配置类,等价于@Configuration,使其能够定义@Bean。
当
main()方法调用SpringApplication.run()时,Spring Boot 会启动应用,创建 Spring 应用上下文(ApplicationContext),并自动扫描、加载所有的 bean、配置类和组件。
2. 组件的自动扫描和依赖注入
- 组件扫描(
@ComponentScan):当启动类启动时,@ComponentScan会扫描当前包及其子包下的所有类,找到标记了 Spring 注解的类(如@Controller,@Service,@Repository,@Component),并将这些类注册为 Spring 管理的 bean。 - 依赖注入(DI,Dependency Injection):Spring 会通过依赖注入的方式,将需要的组件注入到其他组件中。例如,Controller 类中的 Service 实例,Service类中的 Repository实例,都是通过构造函数或字段注入的。
@Autowired注解:用于告诉 Spring 自动注入依赖。
3. 模块之间的启动与协作
- Controller 层与 Service 层的交互:
Controller是处理 HTTP 请求的入口,它接收客户端请求并返回响应。- 在
Controller中,通常通过依赖注入(如@Autowired)的方式,调用业务逻辑层的Service类。例如,一个UserController可能会注入UserService,调用其方法来处理与用户相关的业务逻辑。
- Service 层与 Mapper 层的交互:
Service是业务逻辑的核心层,它处理具体的业务规则和流程。- 如果需要访问数据库,
Service会通过依赖注入调用Mapper类(通常是接口,使用@Mapper注解)。Mapper使用数据库访问框架(如 MyBatis、JPA)来进行增删改查操作,返回的数据会交给Service层处理后返回给Controller。
- Service 层与其他 Service 层的交互:
- 一个服务可能会依赖于其他服务。例如,订单服务
OrderService可能需要调用用户服务UserService获取用户信息。这也是通过依赖注入完成的。
- 一个服务可能会依赖于其他服务。例如,订单服务
4. 数据处理流程
- 请求流程:
- 当一个 HTTP 请求发出时,
DispatcherServlet作为 Spring MVC 的核心控制器,首先拦截请求,然后根据 URL 路径找到对应的Controller,并将请求转发给相应的方法处理。 Controller方法会处理请求参数,并通过调用Service来执行具体的业务逻辑。
- 当一个 HTTP 请求发出时,
- 业务逻辑处理:
Service负责处理业务逻辑,通常通过注入Mapper类与数据库交互,获取或保存数据。
- 数据返回:
Service将处理后的数据返回给Controller,Controller再将数据封装成 JSON、XML 或视图等形式,返回给客户端。
5. Spring Security 或 Realm 的认证流程
- 如果项目中包含安全模块(如
realm目录),Spring Boot 可能会集成 Spring Security 或 Shiro 进行用户认证与授权。 - 当用户访问受保护的资源时,
Realm类(用于身份验证的组件)会被调用,通过查询数据库或其他用户数据源,验证用户身份,并检查权限。 - 验证通过后,Spring Security 会允许请求继续,进入
Controller处理业务逻辑;否则,用户将被重定向到登录页面或显示未授权的错误信息。
6. 配置类的作用
config目录下的配置类会在项目启动时由 Spring 自动加载,并根据项目的需求,配置必要的 bean。- 例如,安全配置类可以定义哪些 URL 需要认证、哪些请求不需要认证;数据源配置类会定义数据库连接的细节;跨域配置类会设置哪些域名可以访问此应用的资源等。
7. 测试的启动
- 测试类通常位于
test目录下。通过@SpringBootTest注解,测试类可以启动一个 Spring 上下文,用于进行集成测试,确保各个模块的正确交互和功能。
8. 主线程与子线程
- Spring Boot 项目默认在主线程中启动。但如果项目中有异步任务、定时任务等,可能会启动多个子线程来并行处理。
- 例如,通过
@Async注解,Spring 可以启用异步任务,在后台线程中执行不会阻塞主线程的操作。
总结:
- 启动类:通过
@SpringBootApplication自动扫描和启动项目。 - 组件扫描:扫描并注册所有 Spring 管理的组件(Controller、Service、Repository 等)。
- 依赖注入:不同层(Controller、Service、Mapper)之间通过依赖注入协作处理业务。
- 请求处理:客户端请求经由
Controller调用Service,最终访问Mapper执行数据库操作。 - 认证授权:通过 Spring Security 或 Shiro 进行安全控制。
- 配置类与测试类:配置类定义应用的各种设置,测试类用于验证功能。
项目启动的核心机制是 Spring Boot 的自动配置 和 依赖注入,它们确保了各个模块能够自动协作和启动。
10. Java什么情况下会产生内存溢出
- 堆溢出,不断的声明新的对象实例
- 虚拟机栈和本地方法栈溢出,线程请求的栈深度大于虚拟机所允许的最大深度、扩展栈容量无法申请到足够的内存。
- 方法区和运行时常量池溢出,一直创建字符串,使得字符串常量池溢出
- 本机的内存溢出,excel表中的数据太多,无法完全放到内存中,如果你要一起读出全部的数据,会发生内存溢出