AFLGo源码阅读-1
首先还是要从基础的C语言语句开始补起。
AFL-代码覆盖率及其相关概念
原文:https://www.freebuf.com/vuls/197672.html
1. 代码覆盖率(Code Coverage)
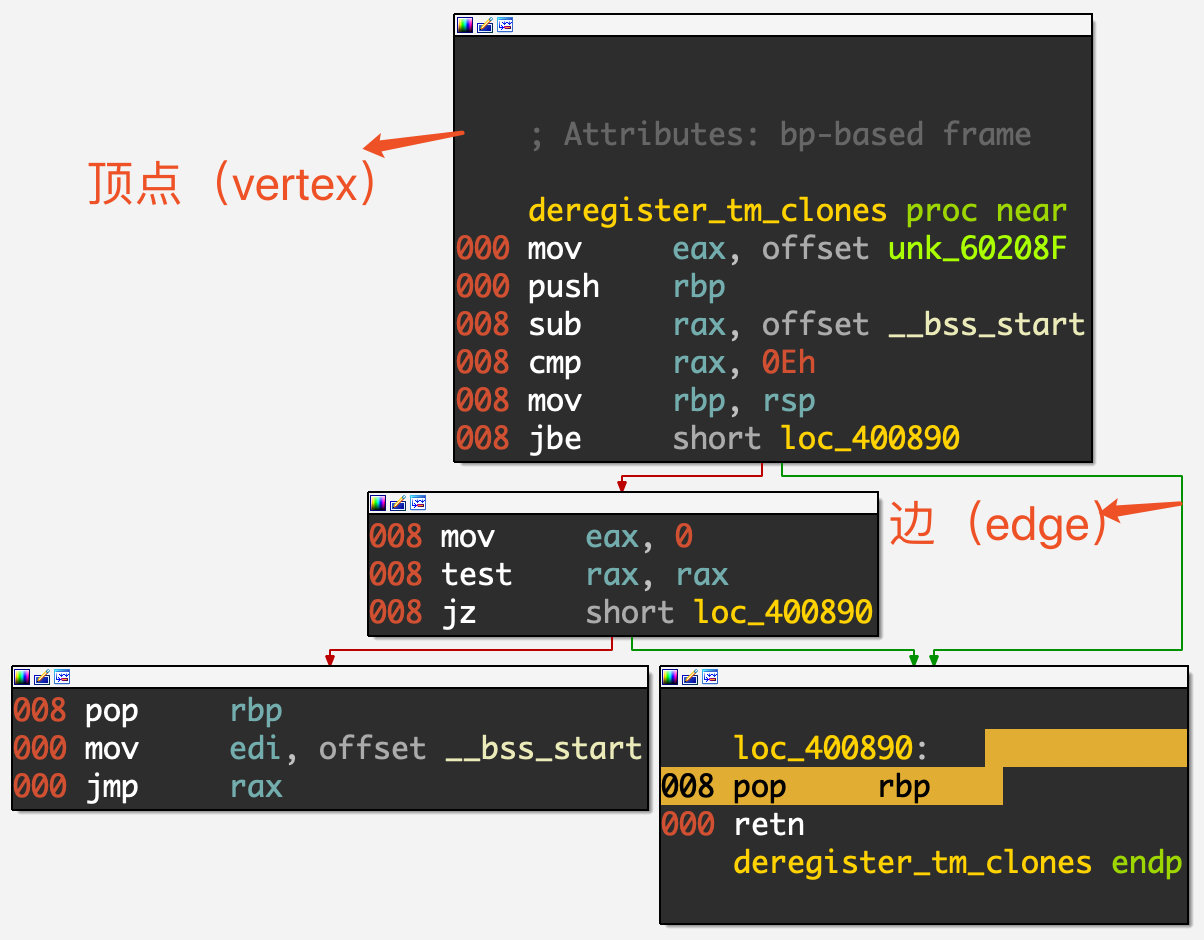
代码覆盖率是一种度量代码的覆盖程度的方式,也就是指源代码中的某行代码是否已执行;对二进制程序,还可将此概念理解为汇编代码中的某条指令是否已执行。其计量方式很多,但无论是GCC的GCOV还是LLVM的SanitizerCoverage,都提供函数(function)、基本块(basic-block)、边界(edge)三种级别的覆盖率检测,更具体的细节可以参考LLVM的官方文档。
2. 基本块(Basic Block)
缩写为BB,指一组顺序执行的指令,BB中第一条指令被执行后,后续的指令也会被全部执行,每个BB中所有指令的执行次数是相同的,也就是说一个BB必须满足以下特征:
- 只有一个入口点,BB中的指令不是任何跳转指令的目标。
- 只有一个退出点,只有最后一条指令使执行流程转移到另一个BB

3. 边(edge)
我们可以将程序看成一个控制流图(CFG),图的每个节点表示一个基本块,而edge就被用来表示在基本块之间的转跳。知道了每个基本块和跳转的执行次数,就可以知道程序中的每个语句和分支的执行次数,从而获得比记录BB更细粒度的覆盖率信息。
4. 元组(tuple)
具体到AFL的实现中,使用二元组(branch_src, branch_dst)来记录当前基本块 + 前一基本块 的信息,从而获取目标的执行流程和代码覆盖情况,伪代码如下:
cur_location = <COMPILE_TIME_RANDOM>; //用一个随机数标记当前基本块
shared_mem[cur_location ^ prev_location]++; //将当前块和前一块异或保存到shared_mem[]
prev_location = cur_location >> 1; //cur_location右移1位区分从当前块到当前块的转跳实际插入的汇编代码,如下图所示,首先保存各种寄存器的值并设置ecx/rcx,然后调用__afl_maybe_log,这个方法的内容相当复杂,这里就不展开讲了,但其主要功能就和上面的伪代码相似,用于记录覆盖率,放入一块共享内存中。
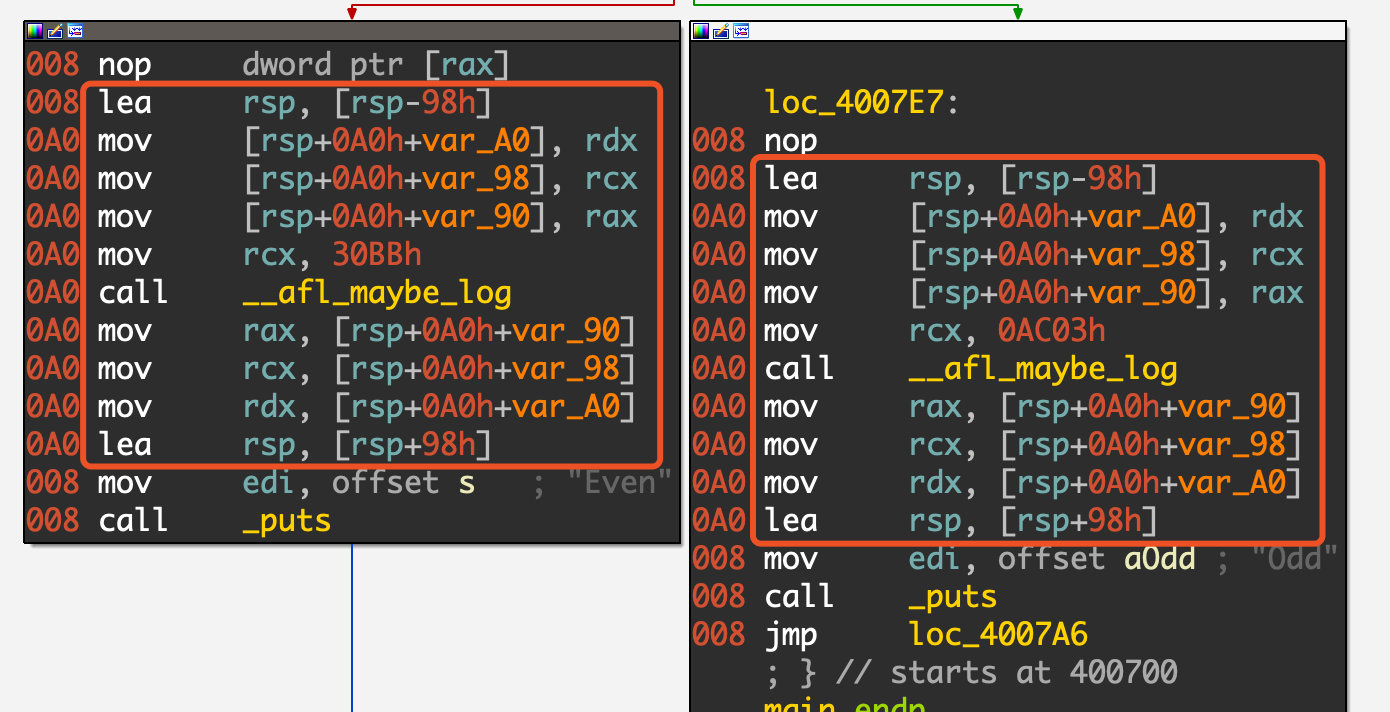
关于这个过程后续肯定要弄的非常清楚才行, 因为要添加一个基于基本块覆盖率的模拟退火算法,这样的扩展应该加在什么地方,以及怎么实现都需要把这个过程弄清楚。
C 知识
C 预处理
C 预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。简言之,C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。我们将把 C 预处理器(C Preprocessor)简写为 CPP。
所有的预处理器命令都是以井号(#)开头。它必须是第一个非空字符,为了增强可读性,预处理器指令应从第一列开始。下面列出了所有重要的预处理器指令:
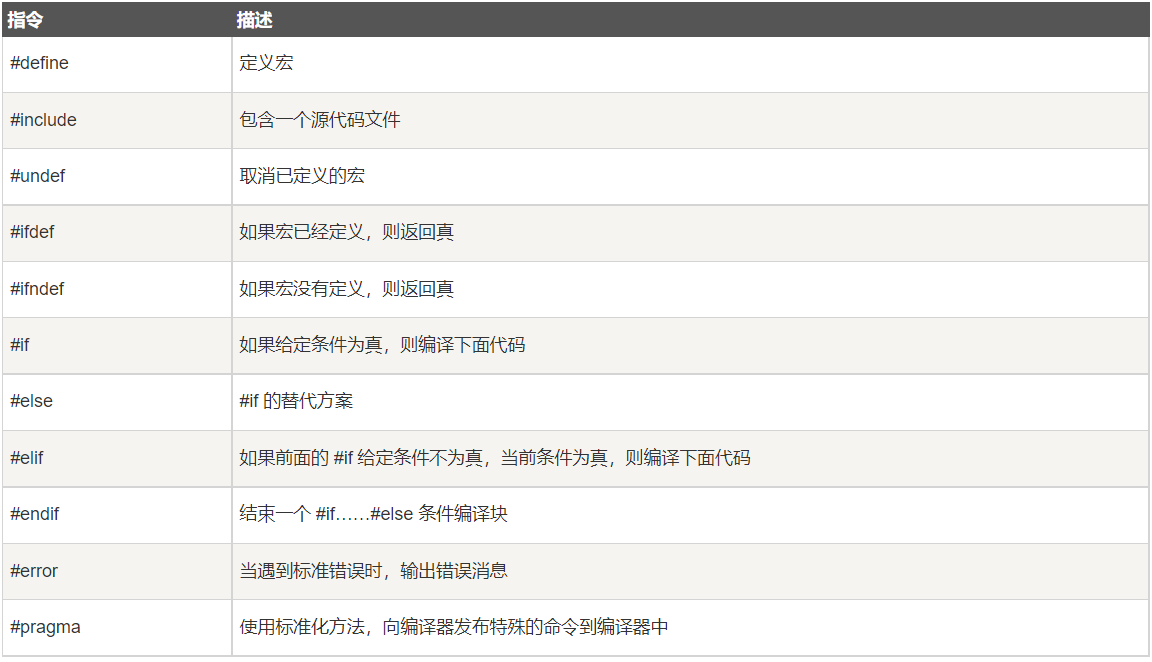
其他的详见菜鸟教程。
https://www.runoob.com/cprogramming/c-preprocessors.html
C/C++ 中 volatile 关键字详解
C/C++ 中的 volatile 关键字和 const 对应,用来修饰变量,通常用于建立语言级别的 memory barrier。这是 BS 在 “The C++ Programming Language” 对 volatile 修饰词的说明:
A volatile specifier is a hint to a compiler that an object may change its value in ways not specified by the language so that aggressive optimizations must be avoided.
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。声明时语法:int volatile vInt; 当要求使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。例如:
volatile int i=10;
int a = i;
...
// 其他代码,并未明确告诉编译器,对 i 进行过操作
int b = i;volatile 指出 i 是随时可能发生变化的,每次使用它的时候必须从 i的地址中读取,因而编译器生成的汇编代码会重新从i的地址读取数据放在 b 中。而优化做法是,由于编译器发现两次从 i读数据的代码之间的代码没有对 i 进行过操作,它会自动把上次读的数据放在 b 中。而不是重新从 i 里面读。这样以来,如果 i是一个寄存器变量或者表示一个端口数据就容易出错,所以说volatile 可以保证对特殊地址的稳定访问。
概念
程序处理中的控制流图和调用图
控制流图–Control Flow Graph
控制流图(Control Flow Graph, CFG)也叫控制流程图,是一个过程或程序的抽象表现,是用在编译器中的一个抽象数据结构,由编译器在内部维护,代表了一个程序执行过程中会遍历到的所有路径。它用图的形式表示一个过程内所有基本块执行的可能流向, 也能反映一个过程的实时执行过程。Frances E. Allen于1970年提出控制流图的概念。此后,控制流图成为了编译器优化和静态分析的重要工具。
原文:
In a control-flow graph each node in the graph represents a basic block, i.e. a straight-line piece of code without any jumps or jump targets; jump targets start a block, and jumps end a block. Directed edges are used to represent jumps in the control flow. There are, in most presentations, two specially designated blocks: the entry block, through which control enters into the flow graph, and the exit block, through which all control flow leaves.
译文:
在控制流图中,图中的每个节点代表一个基本块,即一段没有任何跳转或跳转目标的直线代码;跳转目标开始一个块,而跳转结束一个块。有向边用来表示控制流中的跳转。在大多数演示中,有两个特别指定的块:入口块,控制通过它进入流程图;出口块,所有控制流通过它离开。
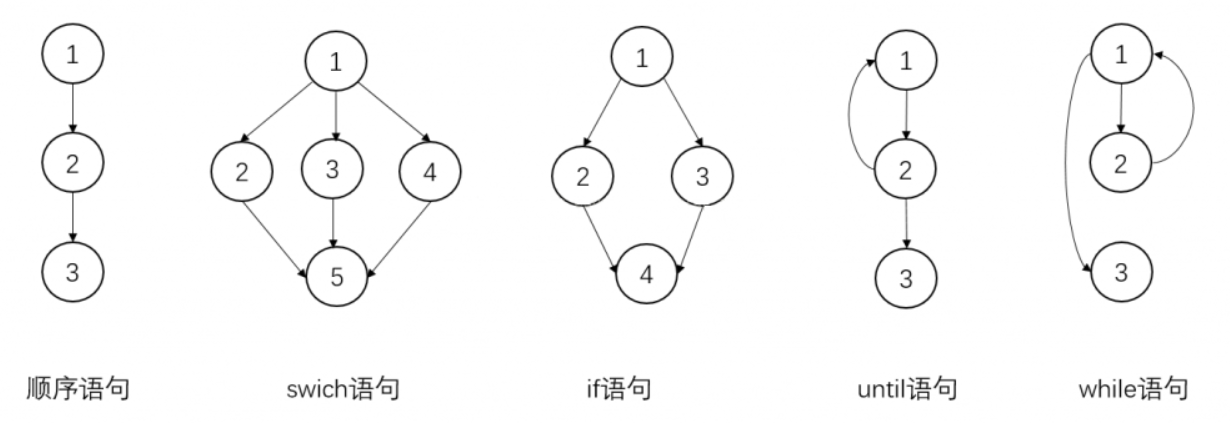
特点:
- 控制流程图是过程导向的
- 控制流程图显示了程序执行过程中可以遍历的所有路径
- 控制流程图是一个有向图
- CFG 中的边描述控制流路径,节点描述基本块
- 每个控制流图都存在2个指定的块:Entry Block(输入块),Exit Block(输出块)
函数调用图 Function Call Graph
插桩怎么实现
Linux
make 和 make install 的区别
简单来说,make 是编译,make install 是安装。
总结:linux编译安装中configure、make和make install各自的作用
./configure是用来检测你的安装平台的目标特征的。比如它会检测你是不是有CC或GCC,并不是需要CC或GCC,它是个shell脚本。
make是用来编译的,它从Makefile中读取指令,然后编译。
make install是用来安装的,它也从Makefile中读取指令,安装到指定的位置。
1、configure
这一步一般用来生成 Makefile,为下一步的编译做准备,你可以通过在 configure 后加上参数来对安装进行控制,比如代码:./configure –prefix=/usr上面的意思是将该软件安装在 /usr 下面,执行文件就会安装在 /usr/bin.同时一些软件的配置文件你可以通过指定 –sys-config= 参数进行设定。有一些软件还可以加上 –with、–enable、–without、–disable 等等参数对编译加以控制,你可以通过允许 ./configure –help 察看详细的说明帮助。
2、make
这一步就是编译,大多数的源代码包都经过这一步进行编译(当然有些perl或Python编写的软件需要调用perl或python来进行编译)。如果 在 make 过程中出现 error ,你就要记下错误代码(注意不仅仅是最后一行),然后你可以向开发者提交 bugreport(一般在 INSTALL 里有提交地址),或者你的系统少了一些依赖库等,这些需要自己仔细研究错误代码。make 的作用是开始进行源代码编译,以及一些功能的提供,这些功能由他的 Makefile 设置文件提供相关的功能,比如 make install 一般表示进行安装,make uninstall 是卸载,不加参数就是默认的进行源代码编译。
make 是 Linux 开发套件里面自动化编译的一个控制程序,他通过借助 Makefile 里面编写的编译规范进行自动化的调用 gcc 、ld 以及运行某些需要的程序进行编译的程序。一般情况下,他所使用的 Makefile 控制代码,由 configure 这个设置脚本根据给定的参数和系统环境生成。
3、make install
这条命令来进行安装(当然有些软件需要先运行 make check 或 make test来进行一些测试),这一步一般需要你有 root 权限(因为要向系统写入文件)
作者:cuteximi_1995 链接:https://www.jianshu.com/p/c70afbbf5172 来源:简书
Makefile
Makefile给我的感觉,就好像是另一种编程语言一样。
