NoteBook阅读
GrammarFuzzer
这一小节讲的是, 将字符串的表现形式变成了树结构. 方便查找和更改
并且呢, 我们优化了之前根据语法生成数据的方法, ***(按照之前的方法生成测试数据,会发现大部分测试数据非常长,并没有很大的意义) *** 因为 如果不对非终止符的最大和最小值进行限制的话, 会分别导致无限循环和测试数据种类不全的问题.
之前算法的问题:
The problem of potentially infinite expansion is only one of the problems with simple_grammar_fuzzer(). More problems include:
It is inefficient. With each iteration, this fuzzer would go search the string produced so far for symbols to expand. This becomes inefficient as the production string grows.— 效率比较低, 因为每次扩展的时候, 要搜素字符串去寻找相应的扩展symbol-(
前面算法里面加了很多正则匹配提取字符串的), 字符串一长效率自然就低下来了. 不过, python中存储字符串的结构是什么? 应该是列表, 这样的话 肯定是不如树的遍历来的快一些.-(不是很清楚到底是因为什么原因导致了, 生成测试字符串效率变高, 但无疑从结果的角度上面看的话, 改进之后的遍历方式确实要比之前快多了)It is hard to control. Even while limiting the number of symbols, it is still possible to obtain very long strings – and even infinitely long ones, as discussed above.—很难控制, 容易生成很长的字符串
统一生成50个测试数据的话:
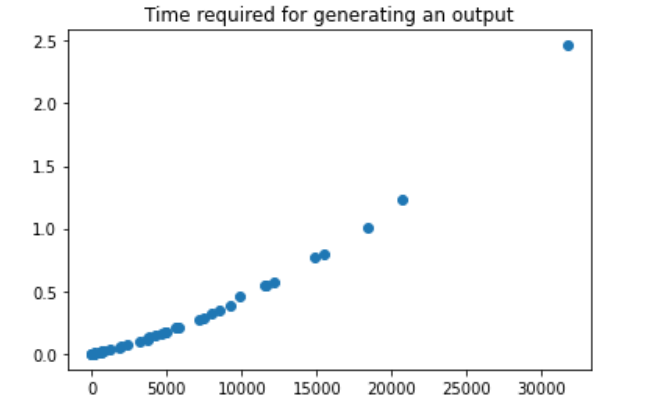
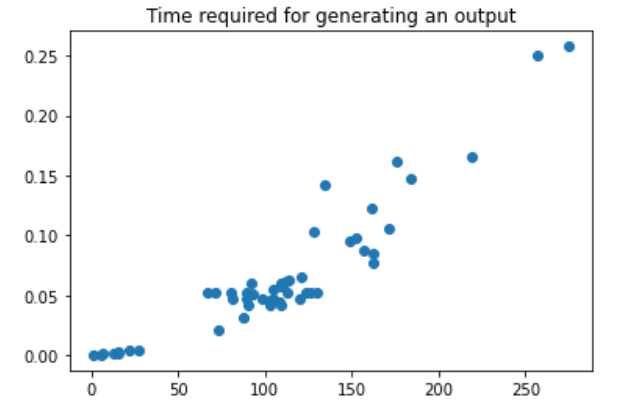
就感觉这一小节都在讲如何构建这个树结构, 以及采用何种策略拓展节点.(在设置的最大最小值的范围内)
The key idea in this chapter, namely expanding until a limit of symbols is reached, and then always choosing the shortest path, stems from Luke
Lessons Learned
- Derivation trees are important for expressing input structure
- Grammar fuzzing based on derivation trees
- is much more efficient than string-based grammar fuzzing,
- gives much better control over input generation, and
- effectively avoids running into infinite expansions.
BNF语法
在上一小节中同样也用过BNF还有EBNF(BNF的一种增强型)
作者:不是Zoe
链接:https://www.zhihu.com/question/27051306/answer/579820547
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
BNF是John Backus 在20世纪90年代提出的用以简洁描述一种编程语言的语言。
基本结构为:<non-terminal> ::= <replacement> non-terminal意为非终止符,就是说我们还没有定义完的东西,还可以继续由右边的replacement,也就是代替物来进一步解释、定义。
举个例子:在中文语法里,一个句子一般由“主语”、“谓语”和“宾语”组成,主语可以是名词或者代词,谓语一般是动词,宾语可以使形容词,名词或者代词。那么“主语”、“谓语”和“宾语”就是非终止符,因为还可以继续由“名词”、“代词”、“动词”、“形容词”等替代。
例1. <句子> ::= <主语><谓语><宾语>
例2. <主语> ::= <名词>|<代词>
例3. <谓语>::=<动词>
例4. <宾语>::=<形容词>|<名词>|<代词>
例5. <代词>::=<我>
例6. <动词>::=<吃>
例7. <动词>::=<喜欢>
例8. <名词>::=<车>
例9. <名词>::=<肉>如上,在::=左边的就是non-terminal非终止符,右边的就是replacement,可以是一系列的非终止符,如例1中的replacement便是后面例234左边的非终止符,也可以是终止符,如例56789的右边,找不到别的符号来进一步代替。因此,终止符永远不会出现在左边。一旦我们看到了终止符,这个描述过程就结束了。
py高阶用法
可变参数&&关键字参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple,而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def test(*a):
print(a)
test(1,2,3,4)
>>> (1, 2, 3, 4)def test1(**a):
print(a)
test1(name="test",name1="test1")
>>> {'name': 'test', 'name1': 'test1'}除了函数的传参, 在赋值的语句中也会出现可选参数
a,b,c = [1,2,3]
print("a b c",a,b,c)
a,b,c,*d = [1,2,3]
print("a b c d",a,b,c,d)
>>> a b c 1 2 3
>>> a b c d 1 2 3 []repr() 函数
repr() 函数将对象转化为供解释器读取的形式。
参数
object – 对象。
返回值
返回一个对象的 string 格式。
这个函数有一说一, 还是不理解到底用处是啥. 有的时候传参不加repr(a)会说a缺少某个属性, 但是repr(a)按照上面的理解的话, 也只是变成了一个字符串. 那为什么就莫名其妙不缺少这个属性了.~~
递归加循环的写法
def all_terminals(tree: DerivationTree) -> str:
(symbol, children) = tree
if children is None:
# This is a nonterminal symbol not expanded yet
return symbol
if len(children) == 0:
# This is a terminal symbol
return symbol
# This is an expanded symbol:
# Concatenate all terminal symbols from all children
return ''.join([all_terminals(c) for c in children])any()函数

集合set()
a={1,2,3}
b={4,5,6}
c= a|b # 把a b集合拼接在一起,不重复的那种
print(c)
>>>{1, 2, 3, 4, 5, 6}print()
我这是来学习fuzz的? 还是在重新学习python的详细编程?