NoteBook阅读
Grammar Coverage
在之前, 按照语法去去扩展生成字符串的时候, 总是把各种扩展被选择的可能性相等化. 但是呢, 对于产生详细的综合性测试数据来说, 更看重种类的最大化.(不一次又一次地重复相同的扩展)
所以, 这小节就是为了解决这个问题. 当然, 在我们上一节的扩展中, 我们使用了maxcost和mincost两种方法, 也确实在一定程度上, 增大了种类的多样性,同时也避免了无限扩展的发生. 可能这一节会对这个问题展开更详细地解答把.
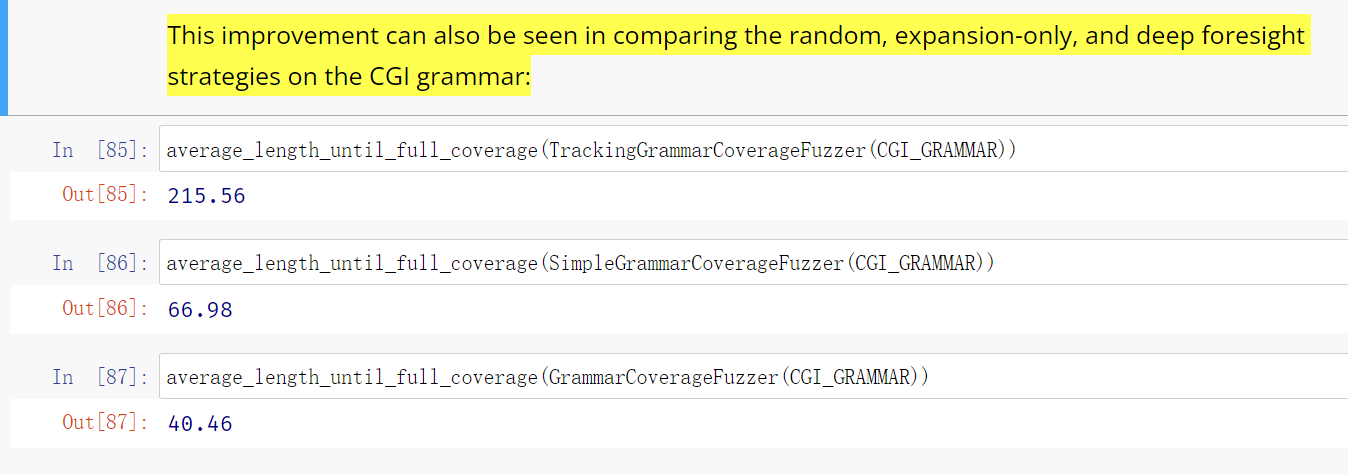
毕竟从理论上来说, 更多地对产生输入数据路径的覆盖(
更高的语法覆盖率)理论上会产生更高的代码覆盖率, 也就更有可能触发新的bug. 这也是这部分工作的意义
Synopsis
This chapter introduces GrammarCoverageFuzzer, an efficient grammar fuzzer extending GrammarFuzzer from the chapter on efficient grammar fuzzing. It strives to cover all expansions at least once, thus ensuring coverage of functionality.
In the following example, for instance, we use GrammarCoverageFuzzer to produce an expression. We see that the resulting expression covers all digits and all operators in a single expression.
>>>> '-(2 + 3) * 4.5 / 6 - 2.0 / +8 + 7 + 3'Lessons Learned
- Achieving grammar coverage quickly results in a large variety of inputs.
- Duplicating grammar rules allows to cover elements in specific contexts.–这个点,我是真的不太理解, 相当于复制了很多副本进来. 这样就能实现很覆盖语法路径?
- Achieving grammar coverage can help in obtaining code coverage.—这个东西, 要具体问题具体分析, 在有些问题上面, 语法覆盖率和代码覆盖率是正相关. 但并不代表所有的问题都是这样.
